|
|
電子情報通信学会 - IEICE会誌 試し読みサイト
© Copyright IEICE. All rights reserved.
|
|
|
電子情報通信学会 - IEICE会誌 試し読みサイト
© Copyright IEICE. All rights reserved.
|
データサイエンスにおけるデータ抽象化によるデータ理解へのアプローチ
小特集 5.
データ解析における特徴選択
Feature Selection for Data Analysis
Abstract
機械学習で取り扱われるデータは,値のベクトルで与えられることが一般的であり,ベクトルの次元を特徴と呼ぶ.特徴選択は,分析の目的に照らして,意味のある特徴を選択するための技術であり,情報理論・統計を手段として用いる.特徴選択は,機械学習における古典的な難問の一つであり,分析の目的が最初に与えられている教師あり学習ではNP-困難であり,教師なし学習では解が一意に定まらない本質的な多義性が難問であるゆえんである.ビッグデータ分析では,膨大な情報雑音を除去する必要があり,重要な技術である.
キーワード:特徴,特徴選択,教師あり学習,教師なし学習
特徴選択は,機械学習における古典的な問題の一つであり,長期にわたって多大な貢献がなされたが,いまだに完全な解決を見ていない難問である.まず,特徴とは何かというところから話を始めよう.我々が,現象を認識するとき,現象を観測し,得られた観測値を利用する.現象は,複数の側面を持つため,観測も複数の方法で実施しなければならない.このことから,一つの観測データは,複数の観測値のベクトルとなる.このベクトルの各次元を特徴と呼び,観測ベクトルをインスタンスと呼ぶ.一方,単一のインスタンスだけでは現象の全体は見えないので,多数のインスタンスを用意する.機械学習では,特徴を共有するインスタンスの集まりをデータセットと呼ぶが,データセットは,インスタンスを行,特徴を列とする,行列とみなすことができる(図1).
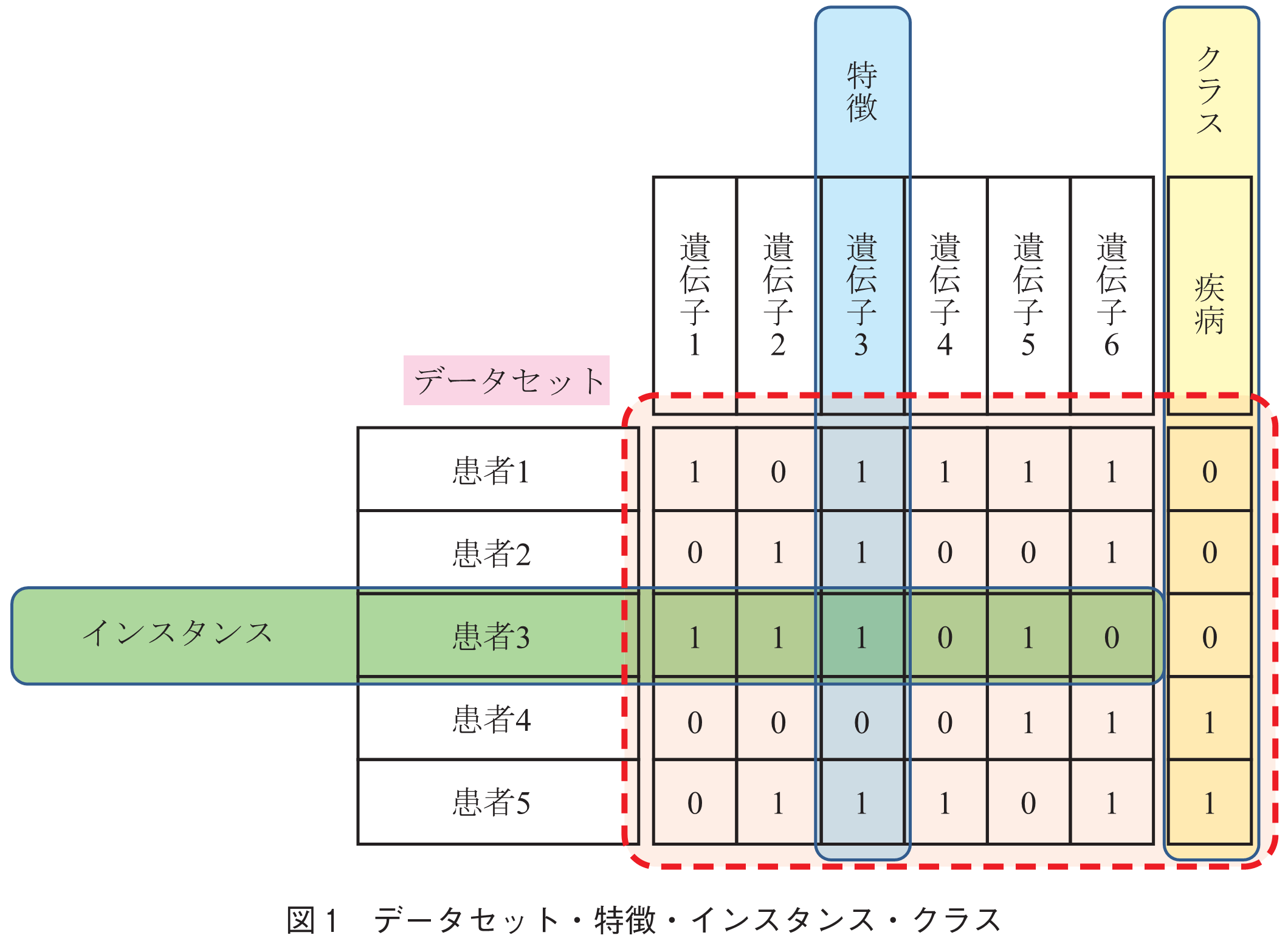
特徴選択の目的は,多数の特徴の中から,分析対象の現象をうまく説明できる少数の特徴を選択することである.古典的な統計では,特徴は説明変数という名前で呼ばれる.また,現象を一つの計量で表現できるとき,機械学習の識別問題ではこの計量をクラス変数などと呼び,統計では目的変数という呼び方をする.例えば,DNA配列を分析して,特定の生理機能の要因となる遺伝子を特定するタスクを考える.各遺伝子が特徴(説明変数)であり,個々のDNA配列が遺伝子を含んでいることを値1,含んでいないことを値0で表せば,DNA配列は0と1を成分とするベクトルに変換される.一方,注目している生理機能が存在するか,否かを,やはり値1と0で表すこととすれば,これがクラス変数(目的変数)の値となる.特徴選択は,情報理論的・統計的な手法を用いて,ラベル変数(目的変数)を説明する特徴(説明変数)を選択する技術であるので,このタスクに有効であることが分かる.
続きを読みたい方は、以下のリンクより電子情報通信学会の学会誌の購読もしくは学会に入会登録することで読めるようになります。 また、会員になると豊富な豪華特典が付いてきます。
電子情報通信学会 - IEICE会誌はモバイルでお読みいただけます。
電子情報通信学会 - IEICE会誌アプリをダウンロード

![]()