|
|
電子情報通信学会 - IEICE会誌 試し読みサイト
© Copyright IEICE. All rights reserved.
|
|
|
電子情報通信学会 - IEICE会誌 試し読みサイト
© Copyright IEICE. All rights reserved.
|
データセンターネットワークの最新動向
小特集 1.
データセンターネットワークの最新動向
Recent Trends for Datacenter Networks
Abstract
Society5.0の中核技術であるCyber-Physical Systemの実現には,エッジ/クラウドコンピューティングでの情報処理能力を飛躍的に向上させる必要がある.それに向けてデータセンターでは,AI/HPC(高性能コンピューティング)を中心とするシステムへの移行を進めており,これまでにない大きな変革を迎えようとしている.本稿では,データセンターネットワーク,光インタコネクション技術,コンピューティングアーキテクチャの観点から,最近の研究開発動向を鳥瞰する.
キーワード:データセンター,エッジコンピューティング,光インタコネクション,コンピューティングアーキテクチャ
内閣府が提唱するSociety5.0(超スマート社会)(1)の実現には,サイバー空間とフィジカル空間を高度に融合させたCPS(Cyber-Physical System)が不可欠である(図1).CPSの実現には,フィジカル空間でのIoT技術や,フィジカル空間とサイバー空間とを連結する大容量データ転送技術(無線通信,光通信)とともに,サイバー空間での情報処理能力の大幅な向上が重要である.これまでフィジカル空間のデータは,郊外の大規模データセンター(Datacenter:以降DC)に送られ処理されてきたが,距離に起因して伝搬遅延が大きくなり,自動運転等のリアルタイムサービスへの対応が困難である.そのため近年では,メトロ網周辺に小形のDC( -DC,エッジDC,small DC等と呼ばれる)を分散配置したエッジコンピューティングの構築が進められている.
-DC,エッジDC,small DC等と呼ばれる)を分散配置したエッジコンピューティングの構築が進められている.
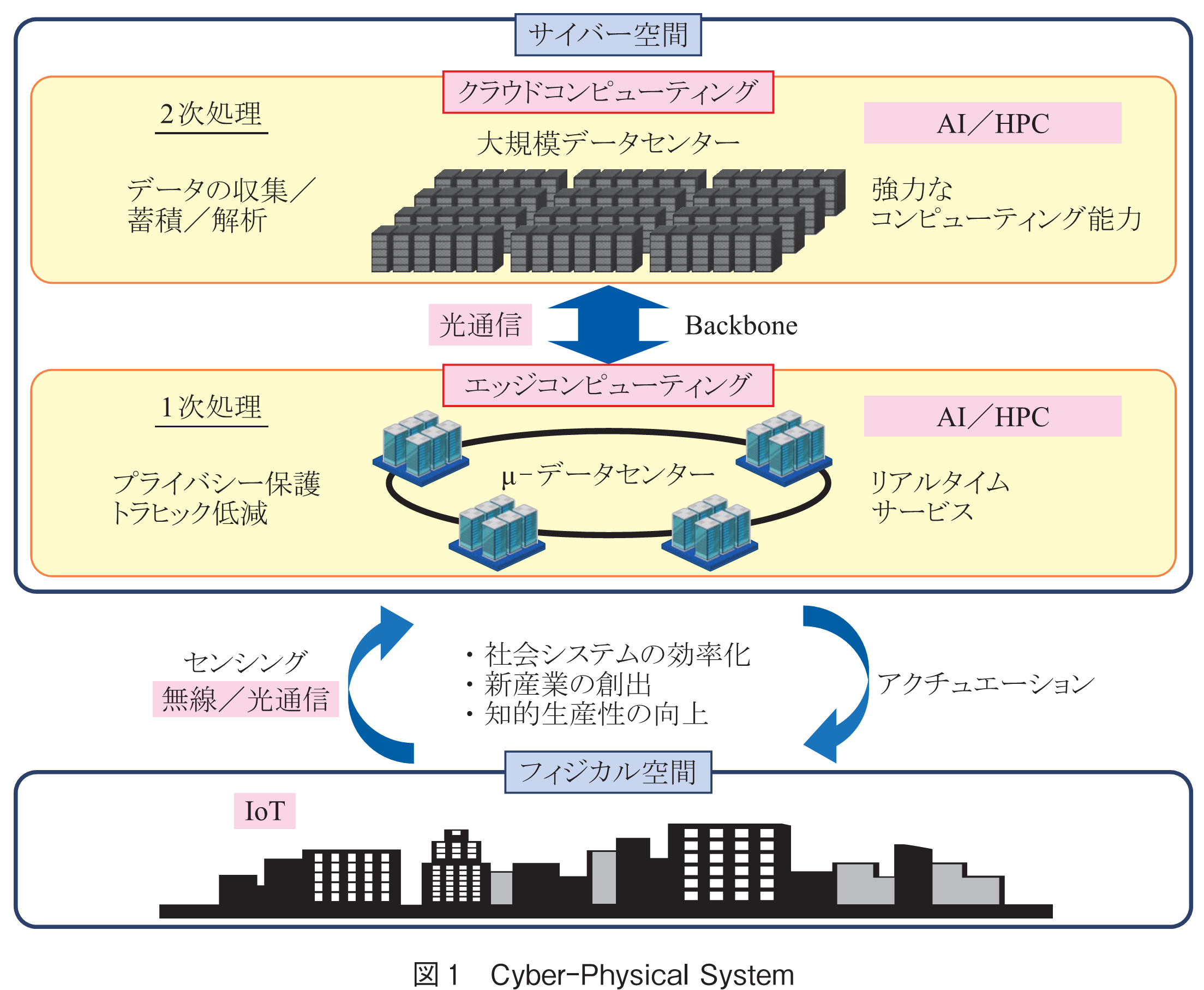
これらサイバー空間の中核を担うDCでは,従来光トランシーバやスイッチ装置,サーバ等の要素技術の高度化に支えられ発展してきた.しかし近年,DCトラヒックの爆発的増加に対し,これら要素技術の成長に遅れが生じ(Growth Gap),様々な面でひずみが生じてきた.例えば,ネットワークの領域では,DCトラヒックの増加>スイッチ装置の容量増加>スイッチ間リンク容量の増加により,光トランシーバの性能がDCネットワークの性能を律速している.更に,サーバの領域では,AIパラメータの増加>プロセッサ等の性能向上>メモリ帯域幅の増加(Memory Wall)により,同様にデータ転送性能が情報処理能力の向上に大きな制約を与えている.
これらの問題を解決するため,近年DCでは様々な破壊的変革を迎えようとしている.ネットワーク領域では,ネットワークアーキテクチャや光インタコネクション技術の変革が進められており,サーバ領域ではAI/HPC(High-performance Computing)を中心とした高度システム構築に向けて,コンピューティングアーキテクチャの大きな変革が検討されている.本稿では,このようなDCが直面する様々な変革に対し,ネットワーク/インタコネクション(ハードウェア)の観点から最近の研究開発動向を概説する.
DCは,元々企業のサーバ室や大型計算機室に存在したが,1990年代に入り様々なインターネットサービスが商用化され,多くの専用事業者によるDCが誕生した.2000年代に入ると,サーバ仮想化技術(1台のサーバで複数の仮想マシンの稼動が可能)や仮想マシンマイグレーション技術(任意のサーバへの仮想マシンの移動が可能)が誕生し,マルチコアサーバの性能が最大限活用可能になるとともに,DCネットワークのトラヒックが大幅に増大した.更に2010年代に入ると,ネットワーク仮想化及びDC仮想化が進展し,DC間が連動することにより,クラウドコンピューティングが本格的に稼動することとなる.
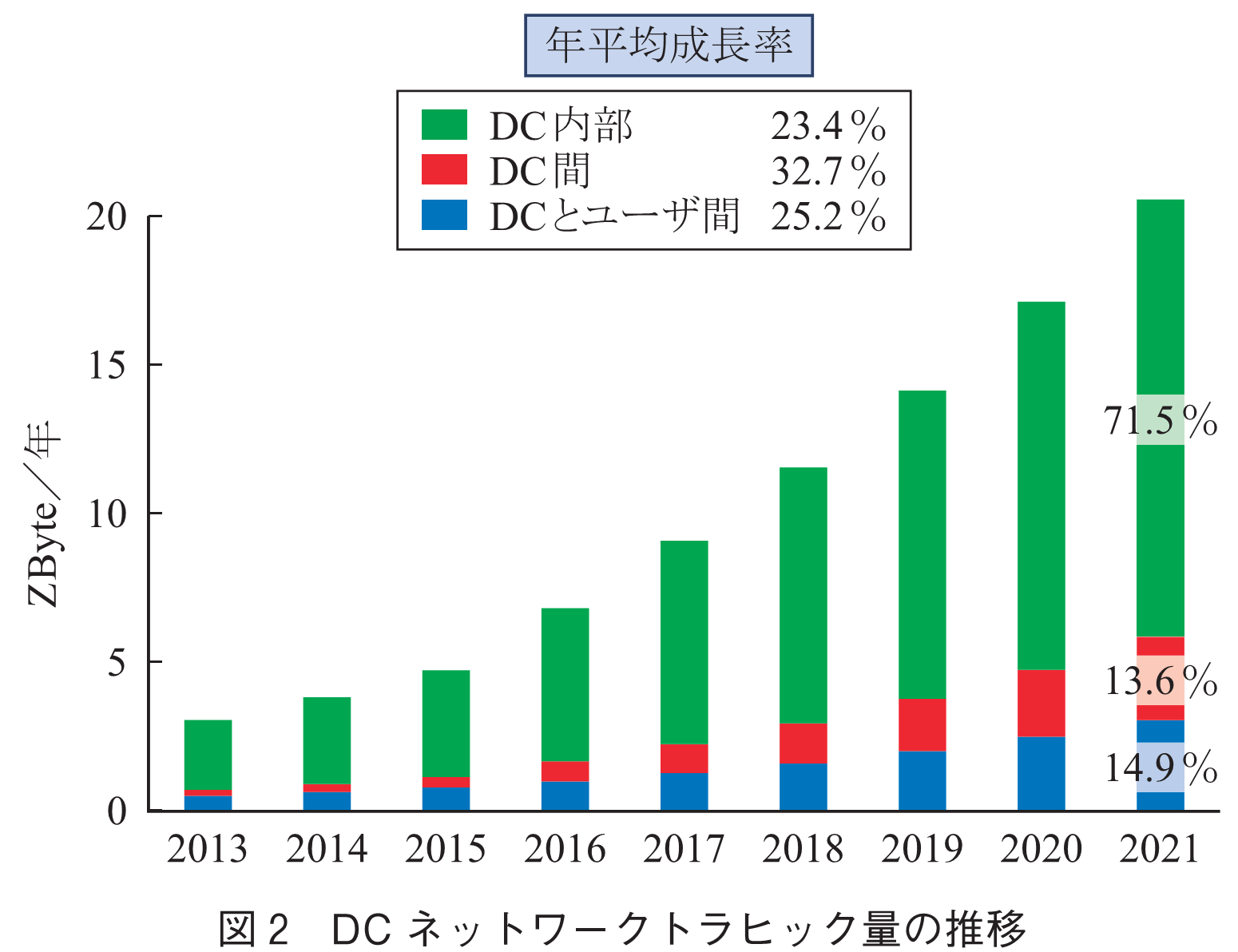
図2は世界のDCトラヒックの推移を示したものである(2).全体では年率25%で増加しているが,AIの導入が先行するDC(例えばGoogleのDC(3))では,年率70%以上で爆発的に増加している.更に,DCにおいて重要な点は,DCとユーザ間のトラヒック(南北トラヒック)の5倍の膨大なトラヒックがDC内部のサーバ間(東西トラヒック)で発生することである.また,クラウドの成長によりDC間トラヒックも急増している.
DCネットワーク拡大の歴史は,このような成長を続けるサービス/トラヒックとの戦いであり,
・Scale-up:ネットワークのリンク容量の向上
・Scale-out:サーバ台数及びネットワークの拡張
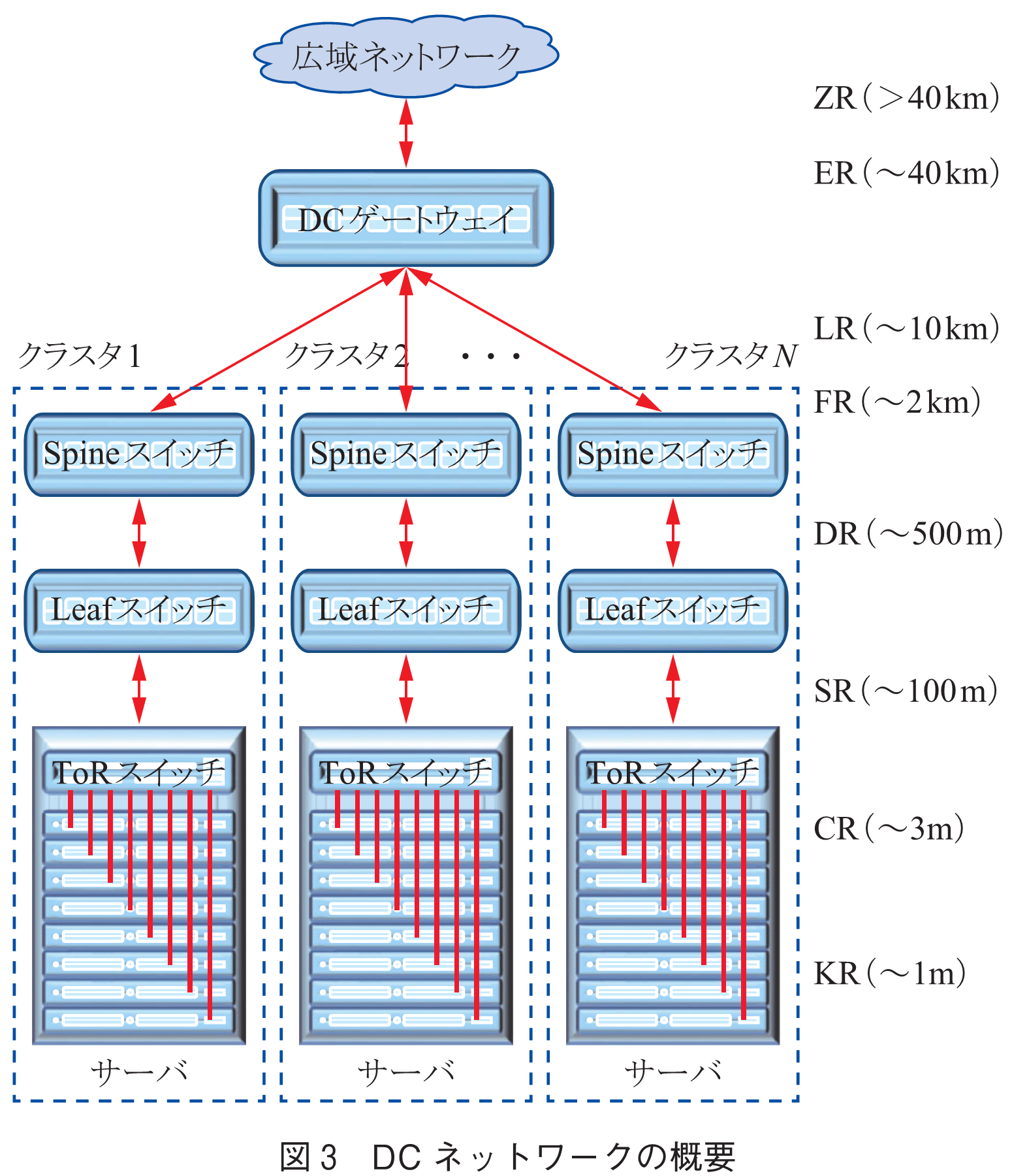
に基づく様々な技術革新に支えられ成長してきた.その結果,近年ではサーバ100万台規模の巨大なDCが作られているが,図3に示すようにサーバ数万台~数十万台ごとのクラスタに分けられ,DCゲートウェイ/WAN(広域ネットワーク)を介して,他のDCやユーザと接続されている.図中右側は各装置間のおおよその距離とそれに対応したトランシーバの規格を表す.DCネットワーク(クラスタ内)で主に使用されるSR/DR光トランシーバは,近年800Gbit/sまで実現されており,更に1.6Tbit/sに向けて開発が進められている.
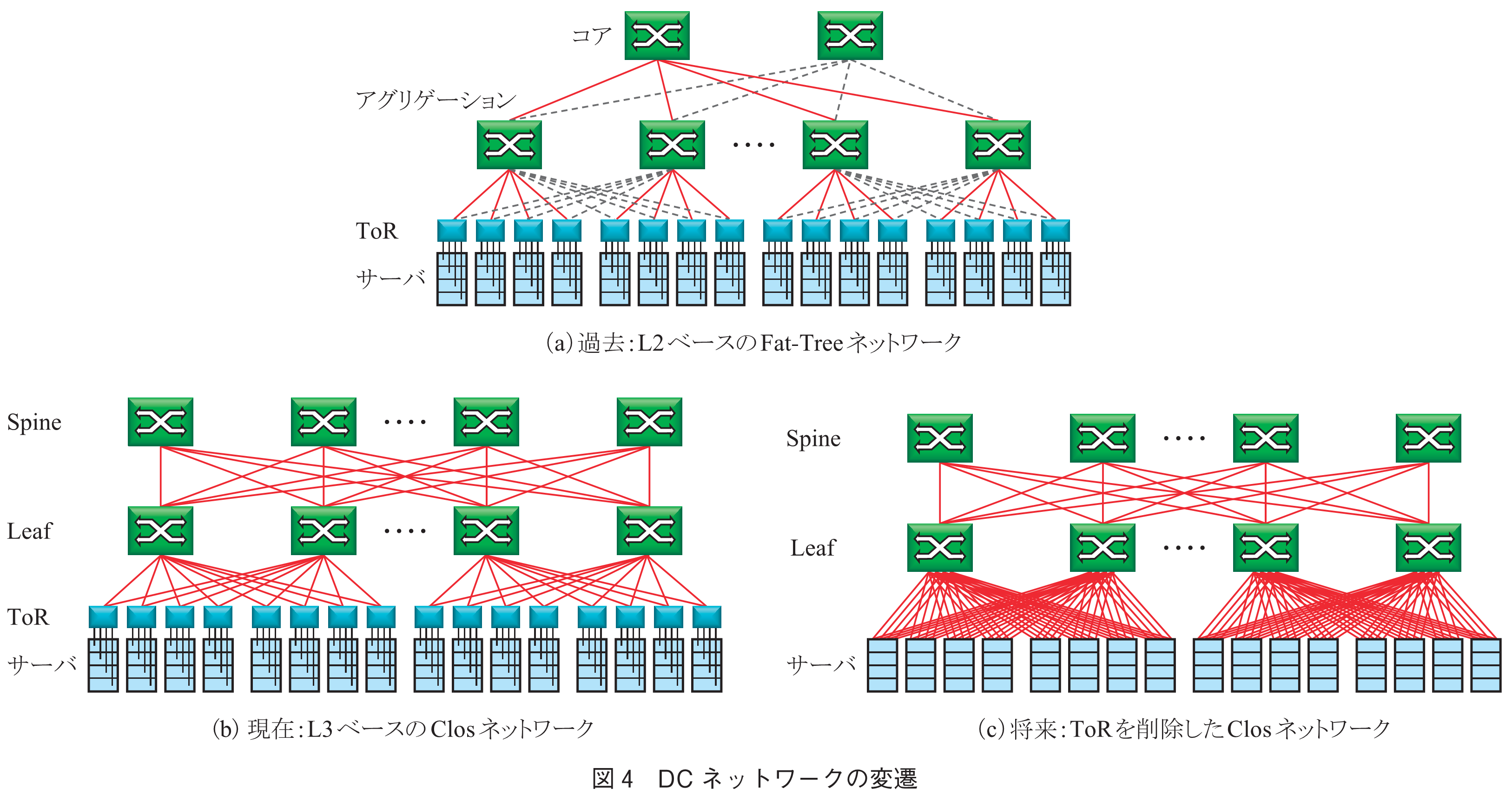
このクラスタ内のネットワーク構成を図4に示す.図4(a)は初期の構成で,ToRスイッチ(Top of Rack,ラックの上部に配置されたスイッチ),アグリゲーションスイッチ,コアスイッチの階層形Fat-Treeトポロジーが用いられていた.ここでは,レイヤ2の制御プロトコルであるSTP: Spanning Tree Protocolが用いられており,ネットワークのループにおいてデータが永続的に流れ続けるのを防止するため,点線のリンクがブロックされることとなる.更に,コアスイッチにデータが集中するため,極めて大容量のスイッチが必要となる.当初,南北トラヒックが主であった時代は本構成で対応してきたが,前述のとおり,サーバ仮想化による東西トラヒックの増大が進むにつれ,ネットワークの帯域不足に起因して拡張性に限界が見えてきた.そのため2000年代中頃から,図4(b)に示すClosネットワーク(3階層のスイッチ装置を相互接続したネットワーク構成の一種.Spineスイッチで折り返されているため,Folded Clos型とも呼ばれる)へ移行され(4),現在での主流となっている.ここでは,多数のToR,Leaf,Spineスイッチがお互いに複数の冗長リンクで連結されており,大幅に転送経路が拡張されている.更に,レイヤ3の経路制御プロトコル(主に,BGP: Border Gateway Protocol)が用いられるため,ループ回避の必要がなくなり,全てのリンクをアクティブに利用することが可能となる.そのため,爆発的に増大する東西トラヒックに対応して,ネットワーク帯域を大幅に拡張することが可能となった.
DCの電力消費量が,2030年には全世界の電力消費量の8~10%程度に増加すると予測されており,低消費電力化が極めて重要な課題である.更に,高度な情報処理能力を必要とするAI/HPCサービスが増加するにつれて,ネットワークでのデータ転送遅延が大きな障害となっている.これら消費電力や遅延問題を解決するため,以下のような幾つかの方策が検討されている.
◆次世代光トランシーバへの移行
光リンクの高速化に伴い,従来のプラガブル光トランシーバでは,信号補償・誤り訂正機能が複雑となり,消費電力及び遅延が上昇する.この問題を解決するために,スイッチASIC(Application Specific Integrated Circuit,スイッチの機能に特化した大規模集積回路.後述の図6参照)近傍に配置した次世代光トランシーバの研究が活発に行われている(3.参照).
◆Store & Forward方式からCut-through方式への移行
従来のStore & Forward方式では,スイッチASICは入力パケット全体をメモリに取り込んだ後にヘッダの宛先を認識し転送処理を行うが,Cut-through方式では,ヘッダ部分を取り込んだ時点で認識・転送を行うために,スイッチでの転送遅延を大幅に短縮できる.これは,入出力のパケットが同一フォーマット(速度変換等がない)であることが必要であり,Spineスイッチでの導入が行われている(4).
◆ネットワーク階層の削減,フラット化
現在は,サーバからの信号は電気配線でToRに送られ,その後高速な光信号としてLeafスイッチに送られる.将来は図4(c)に示すように,サーバから直接高速光信号として出力させることでToRを削除して,ネットワークの階層を削減することが検討されている(5).
◆単一スイッチASICを用いた超多ポートスイッチ
1台のLeaf/Spineスイッチの内部では,多数のスイッチASICを用いてClos構成を組むことで多ポート化(例えば,128ポート)を実現している(6).そのため,サーバ間のデータ転送に対し,最多で9回もスイッチASICを通過することとなる.しかし,将来例えば51.2Tbit/sの大容量スイッチASICを用いて,一つのASICで400Gbit/s×128ポートのスイッチ装置が実現できれば,ASIC数の削減及びサーバ間転送を最多で5回に削減することができる.しかし,現在のプラガブル光トランシーバでこれを実現するのは困難であり,前述の次世代超小形光トランシーバの開発が必要である(5).
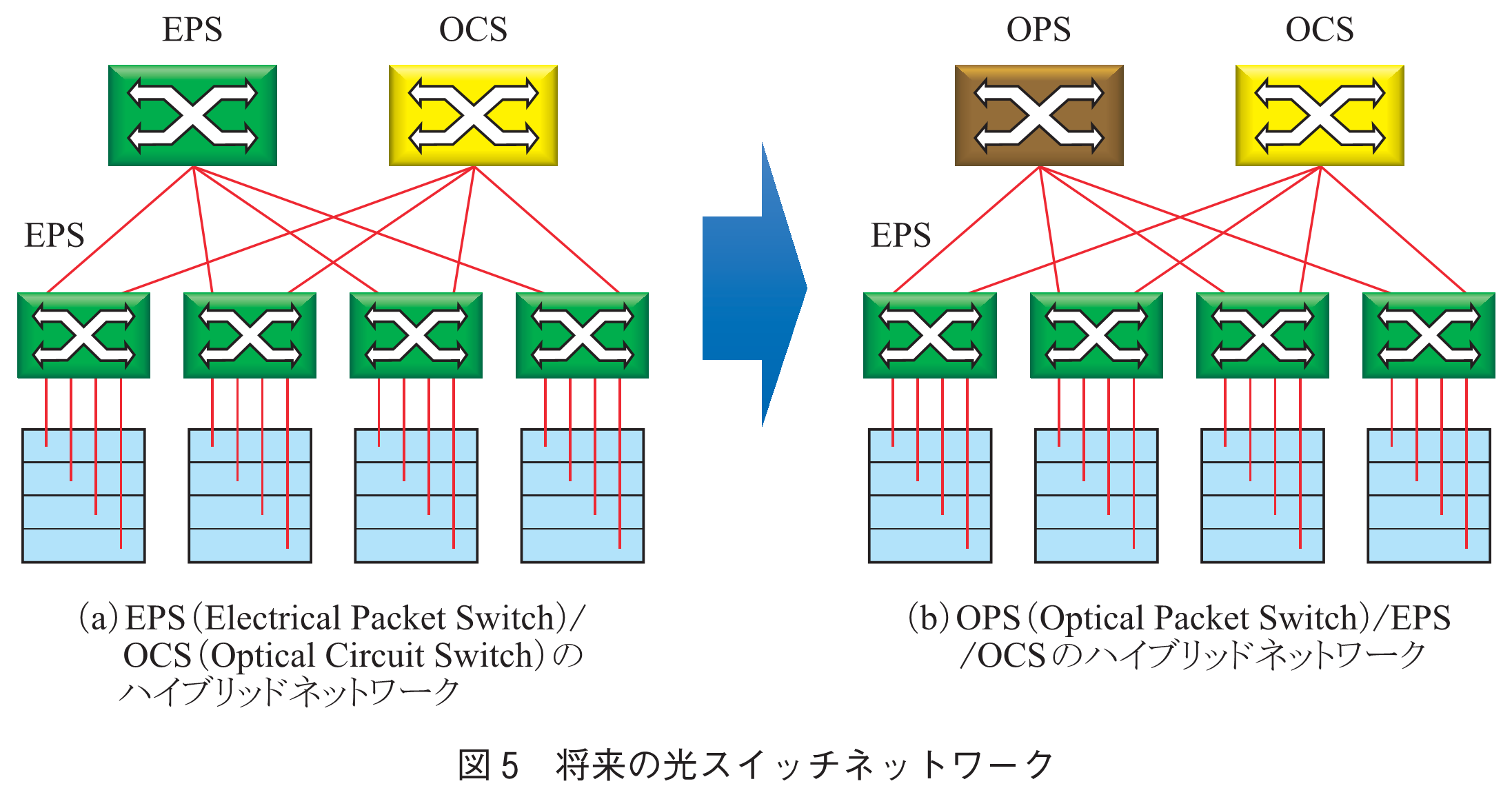
◆光スイッチネットワークへの移行(7)
究極の低消費電力化・低遅延化の方法は,電気スイッチの代わりに光スイッチを用いた光スイッチネットワークの導入である.図5(a)は第1ステップとして,OCS: Optical Circuit Switchと従来のEPS: Electrical Packet Switchのハイブリッドネットワークの概念を示す.OCSは,回線交換方式であり,スイッチ速度はミリ秒オーダと極めて遅く,衝突回避機能を持たない.そのため,パケット単位でのスイッチングではなく,バックアップデータ等の極めて大きなデータのオフロードに用いられる.更に将来には図5(b)に示すように,OPS: Optical Packet Switchの導入が期待される.OPSはEPSと同様にヘッダ認識,スイッチ,バッファの基本三要素を有しており,衝突回避及びパケット単位での高速スイッチングが可能である.しかし,光の状態でこれら機能を実現するのは極めて困難である.特にその中核を担う光スイッチは,高速・低損失・偏波無依存等の要求を満たす必要があり,技術的障壁は極めて高い.そのため,OPSでは比較的ポート数の少ない光スイッチ(16×16程度)に適した新たなトポロジー(トーラス,DCell等)を用いたネットワークが提案されている.光スイッチシステムの詳細は,本小特集4「データセンターにおける光スイッチネットワーク技術の動向」を御覧頂きたい.
現在のスイッチ装置は,基本的にPCB(Printed Circuit Board)上にスイッチASICが置かれ,フロントパネルに装着される光トランシーバとそれぞれ数十cmの電気配線で接続される(図6(a)).また,これが複数台接続されることで,一つのLeaf/Spineスイッチ装置が構成される.スイッチASICは2年ごとに2倍に成長しており(図6(b)),現状では25Tbit/sの大容量ASICが開発されている.しかし,このスイッチASICの成長に伴い,スイッチ装置では以下に示す様々な問題に直面している.
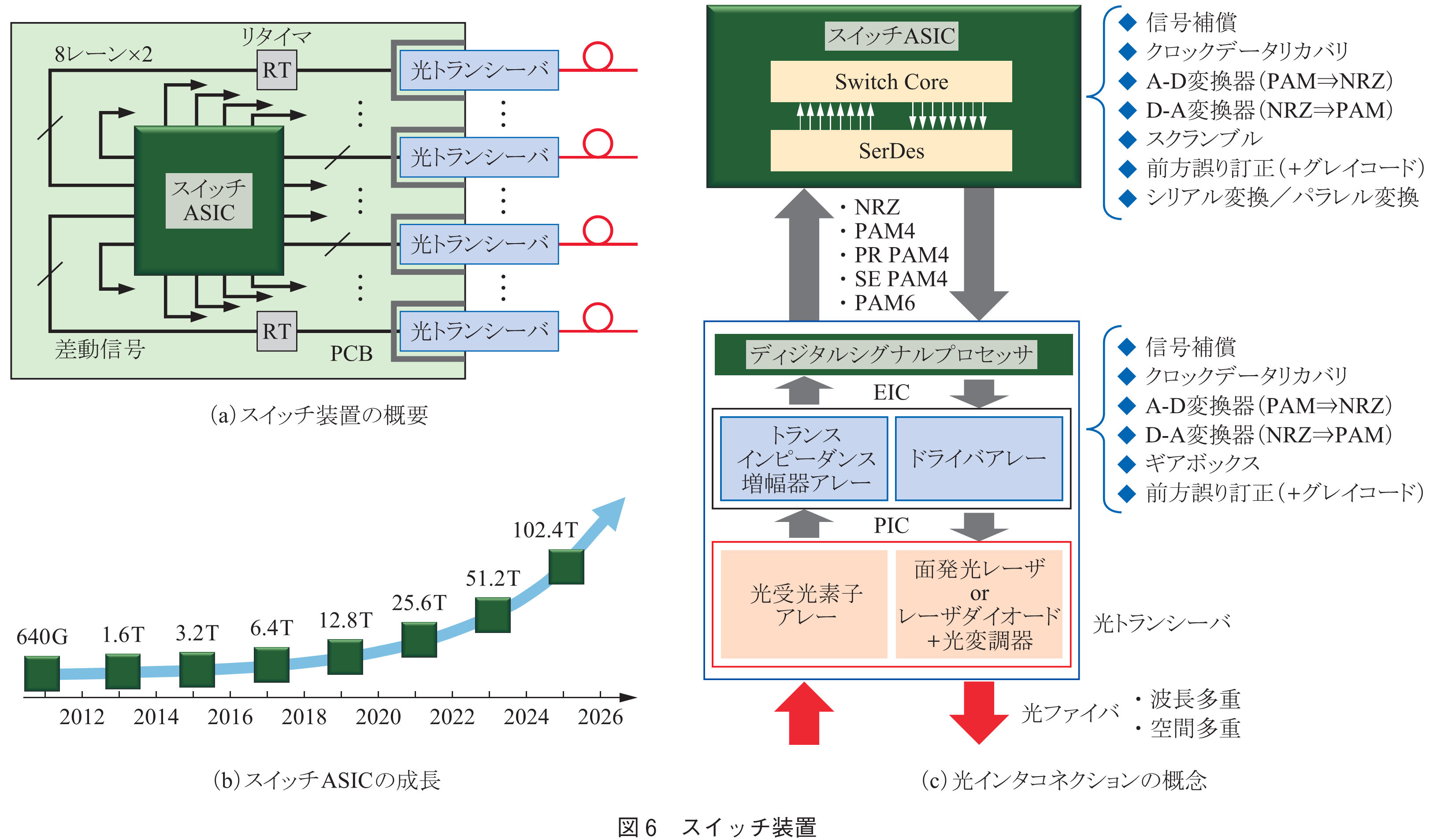
◆実装可能な光トランシーバ数の制限
光トランシーバのフォームファクタ(形状の規格)は,CFPからQSFPへと小形化が進められたが,その後の小形化は困難な状況にある.そのため,フロントパネルに装着可能な光トランシーバ数は1U当り32個程度が限界である.
◆高速・高密度電気配線の問題
PCBとスイッチASICを接続する入出力ピン数には制限があるため(8),32個の各光トランシーバとスイッチASIC間は,入力・出力各8レーンの差動信号(計32本の電気配線)で接続される.現在400Gbit/sの光トランシーバでは50Gbit/sのPAM4(Pulse Amplitude Modulation)信号が用いられているが,電気信号の高速化に伴い,高周波成分の誘電損やクロストークなどに起因した伝送特性(信号波形)の劣化が大きな問題となる.近年,Flyover cable(細線同軸ケーブル)やMegtron系低損失基板が開発されたことで,800Gbit/s光トランシーバが実現可能となったが,1.6Tbit/sへの高速化にはいまだ多くの課題が残っている.
◆信号処理・信号補償の問題
スイッチASICと光トランシーバ間では,信号波形が大きく劣化するため,図6(c)に示す様々な信号処理・信号補償の機能が必要となる.スイッチASICの入出力部には高速信号を内部クロックの並列低速信号に変換するSerDes(Serializer/Deserializer)が集積されており,SerDes本来の機能以外にも信号補償(Equalization)や波形整形(CDR: Clock and Data Recovery),誤り訂正(FEC: Forward Error Correction)等の回路も含まれる.更に4値のPAM4信号の処理には,A-D変換器(ADC, Analog-to-Digital Converter)/D-A変換器(DCA, Digital-to-Analog Converter)が必要となる.光トランシーバ側には,DSP(Digital Signal Processor)チップが搭載され,同様に様々な機能が包含される.現在レーン当り200Gbit/sの高速化が議論されているが(9),そこでは従来不要であったDSP内でのFEC機能や新たな変調方式(PR-PAM4, PAM6/8等)が検討されている.このように従来のプラガブル光トランシーバは,電気信号の高速化に伴い,SerDes/DSP機能が複雑になり,消費電力・遅延が大きく増加するため,限界が見えてきた.
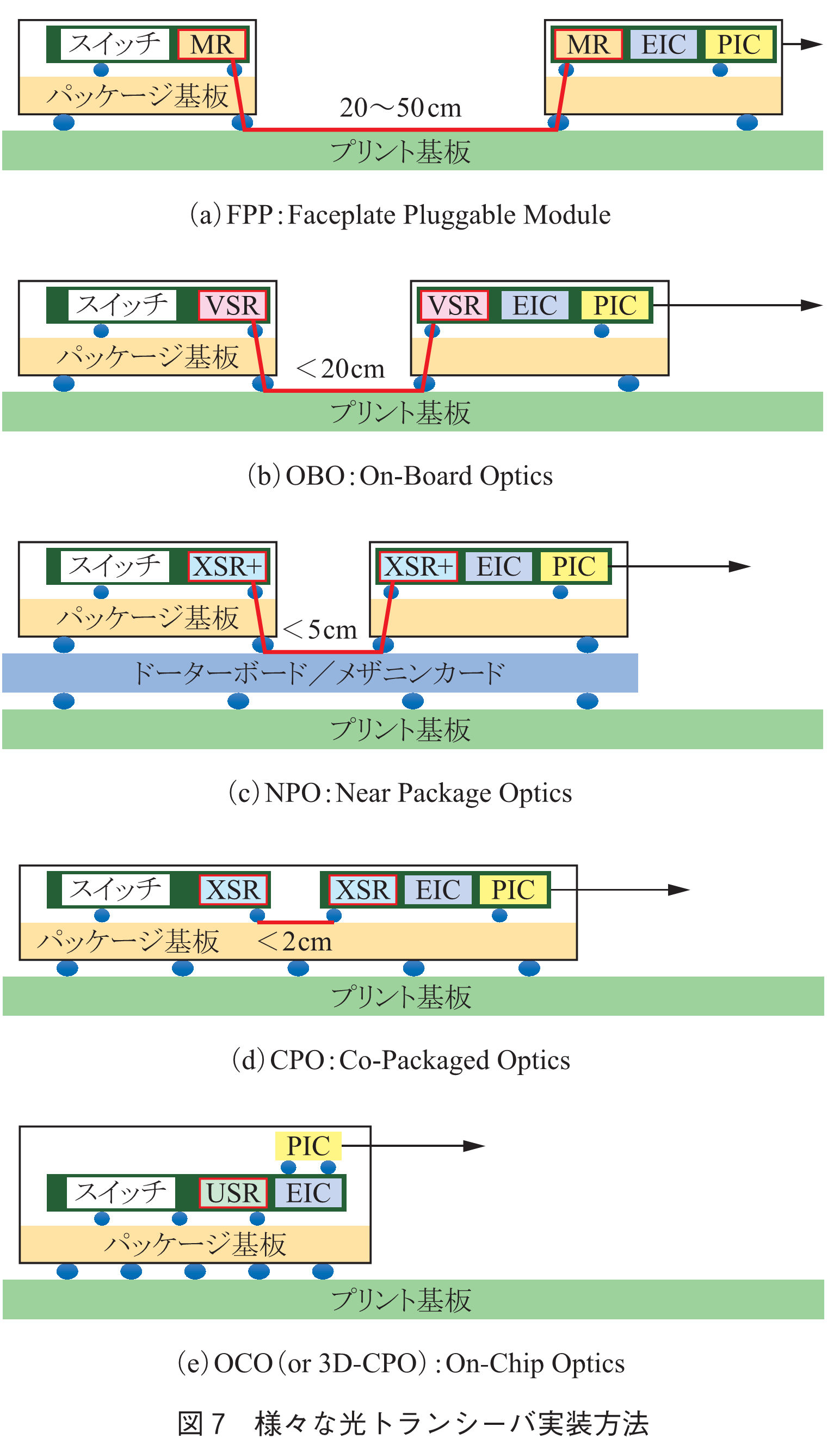
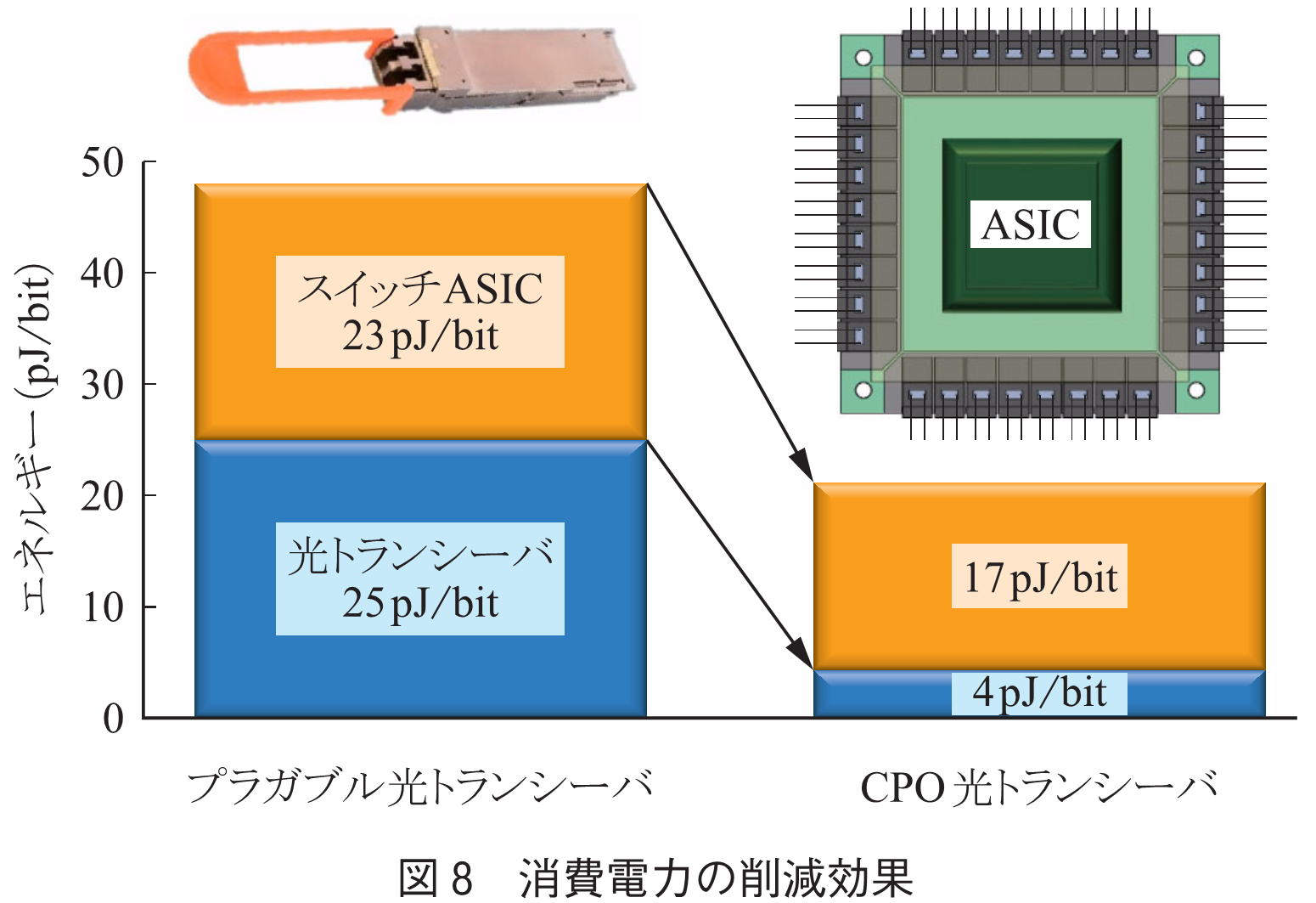
この問題を解決するためには,ASICと光トランシーバの距離を極力近づけ,その間での電気信号劣化を抑えることが重要である.そのため図7に示す様々な実装方法が提案され(5),(10),(11),近年特にNPO/CPOの次世代超小形光トランシーバは世界中で熾烈な開発競争が行われている.図中のXSRやVSR等の記号は,距離(伝送損)に応じたCEI(Common Electrical I/O)規格(12)の名称であり,SerDesやDSPに必要な機能が定義されている.NPO/CPOでは,PCB上の電気配線を用いないため,入出力配線の並列数を増やし,NRZ信号の適用も可能となる.そのためDSP側の信号補償は非常に軽くなり,更にそれ以外の機能は全て削除できるため,大幅な低消費電力化が可能となる.また,信号補償回路等はドライバ等のEIC(Electrical Integrated Circuit)側に集積することで,DSPチップは不要となり,大幅な小形化が可能となる.同様にSerDes側の機能も低減されるため,スイッチASICの消費電力も削減される.その結果,図8に示すように,スイッチを通して1回転送するエネルギーは半分以下に削減可能である.ここでは,400G光トランシーバを想定しており,SerDesの消費電力が8から2pJ/bitに削減されると仮定している.なお,光トランシーバの詳細は,本小特集2「データセンター光インタコネクション技術」を御覧頂きたい.
多数のサーバをネットワークで接続する現状のDCでは,AI/HPCを中心としたコンピューティングシステムの処理能力の向上に限界が見えてきた.そのため,ネットワークだけでなく,サーバの領域でも新たな変革の動きが起こっている.
◆AI機械学習に最適化したネットワーク
近年AIパラメータは爆発的に増大し,AI処理には100個以上のアクセラレータが用いられる.これを従来のサーバシステムで実行するとネットワーク転送遅延が大きな障害となる.図9(a)は,2021年にGoogleが発表したTPUv4の概念図である(13).1枚のTPU(Tensor Processing Unit)ボードには4個のTPUチップが搭載されており,各TPUボードはそれを制御するためのCPUを搭載したTPUホストと接続されている.各TPUボードはTPUホストを介してToRスイッチと接続されており,DCネットワークを通じて外部のストレージやサーバ等とつながっている.更にDCネットワークとは別に,TPUボード間は直接光リンクで接続されており,三次元のトーラスネットワークを構成している(以前のTPUv3では二次元トーラスを採用).システム全体では,4,096チップのTPUチップが搭載されており,それらが部分的にニューラルネットワークを構成することで,多くのAI機械学習の並列処理を可能としている.
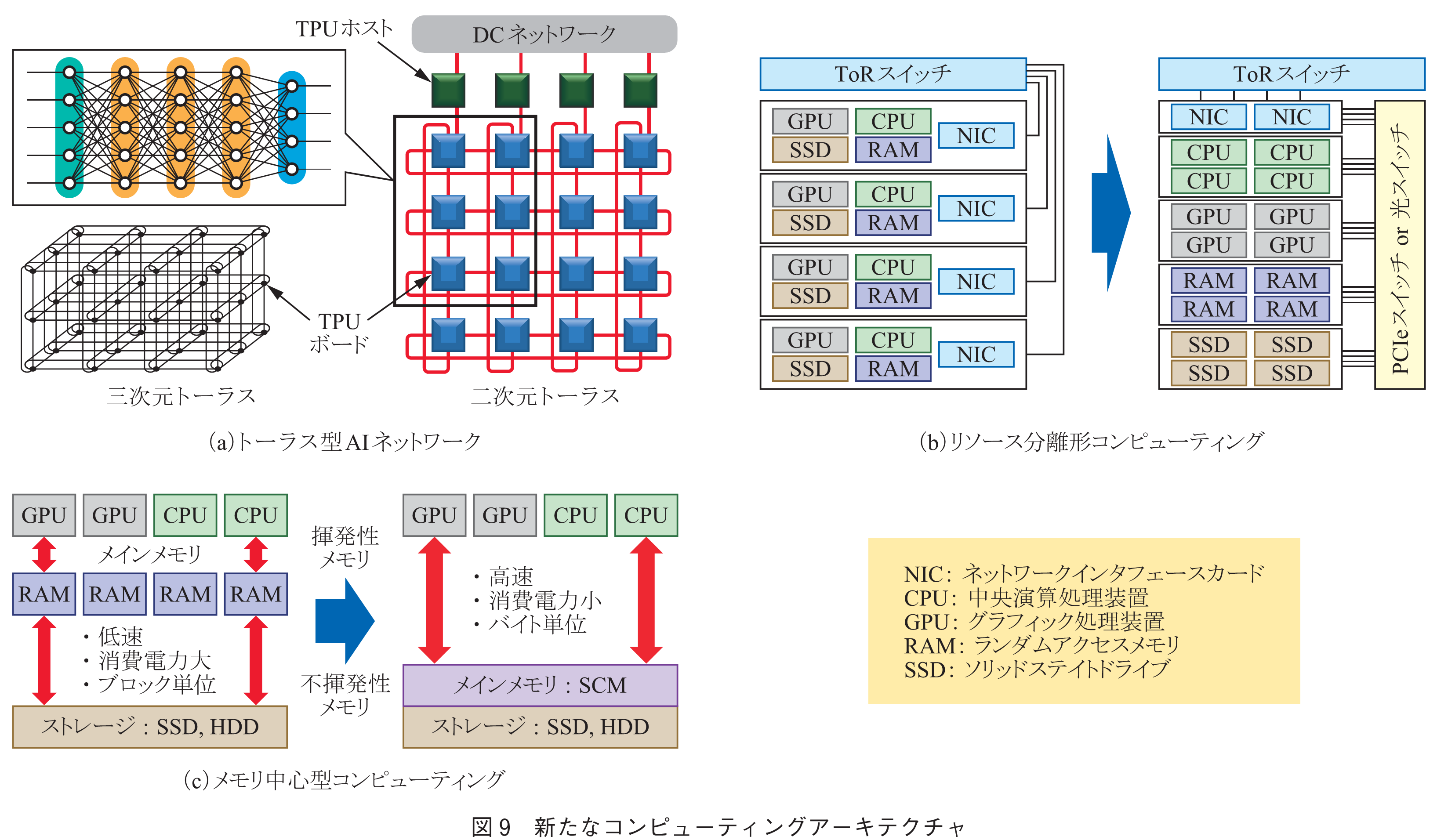
◆リソース分離形(Resource-disaggregated)コンピューティング
従来のシステムでは,図9(b)左に示すように,プロセッサ,アクセラレータ,メモリ,ストレージ等のリソースがセットになったBox型サーバが多数(20~40)ラックに装備され,それぞれのサーバからは,NIC(Network Interface Card)でEtherパケット等にプロトコル変換され,DCネットワークにつながっている.このとき,使用しないリソースが多数発生するため,リソースの利用効率が低下し,エネルギー効率の悪化につながっている.
図9(b)右は,リソース分離形コンピューティングの概念を示す(14).各リソースは分離され,それぞれのプール群が形成され,高速PCIeスイッチ(または光スイッチ)を介して接続される.この概念は2000年代後半頃から提案されているが,近年のAI/HPCの高度化やDMA(Direct Memory Access: CPUを介することなく他のリソースが直接メモリにアクセス可能な技術)の進歩に伴い,変革の動きが加速してきた.このリソース分離形構成のメリットとしては,
・アプリケーションごとに必要なリソースを割当可能
・リソース利用効率,エネルギー効率が大幅に向上
・リソースごとに拡張/縮小,アップグレードが可能
等があるが,逆にデメリットとしては,
・膨大なリンク数・リンク帯域が必要
・異なるリソース間(特にメモリ)での転送遅延の増大
などが懸念される.これらの問題の解決には,前述のCPO光トランシーバを用いた,チップ間の大容量・低遅延光インタコネクト技術の進展が期待されている.更に,図ではラックスケールのイメージであるが,将来はDCスケールに拡張されることが期待される.
◆メモリ中心型(Memory-centric)コンピューティング
現状のシステムでは,不揮発性メモリであるストレージから,個々のCPUやGPUに接続された少量の揮発性主記憶メモリ(DRAM)にデータをコピーし,処理後すぐに再びストレージに書き戻す必要がある(図9(c)左).このとき,DRAMとストレージのアクセス速度には大きな差があり,無駄な時間が発生する.更に,データ転送には1回の計算処理よりも多くのエネルギーを消費する.また,ストレージからはブロック単位での転送しかできないため,主記憶メモリでは不要なデータも受け取る必要があるなど,多くの問題を抱えている.
このような頻繁に発生するデータ移動を極力避けることがメモリ中心型(駆動型)コンピューティングの基本的なコンセプトであり,その1例を図9(c)右に示す(15).究極の狙いとしては,システムの中心に不揮発性の大容量主記憶メモリ(共有メモリ)を配置して,プロセッサ等を直接接続することである.これにより,処理中のストレージとのデータ移動は不要となる(ストレージは処理後のバックアップメモリ).しかし,従来の不揮発性メモリ(SSD, HDD)は,前述のような問題があり,主記憶メモリとして用いるのは困難である.
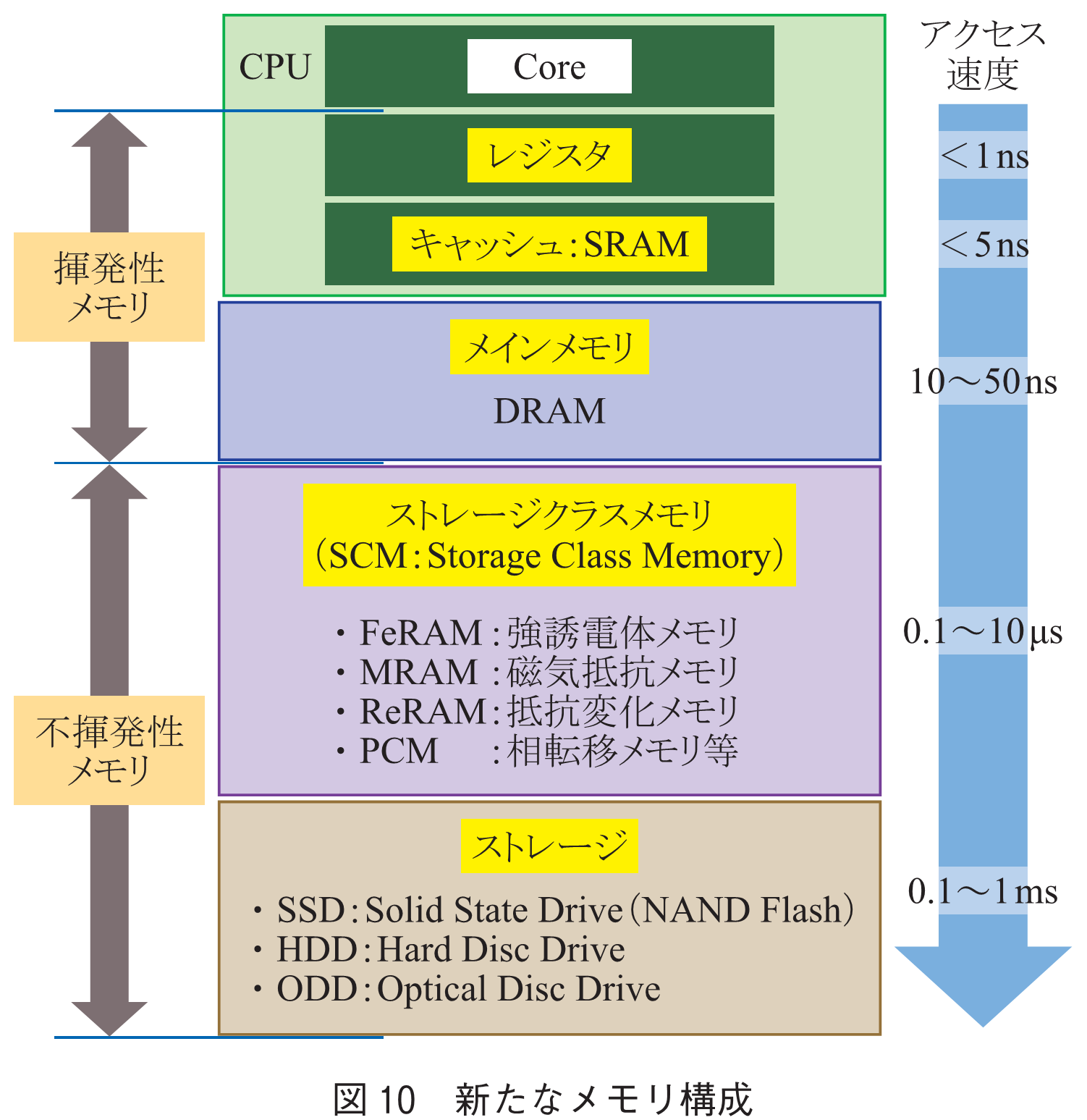
この問題の解決に向けて期待されているのが,次世代メモリと呼ばれるSCM(Storage Class Memory)(16)である(図10).SCMは,不揮発性でありながらDRAMに近い高速性を有し,更にバイト単位での細かなアクセスが可能なため,主記憶メモリとして用いることが可能である.しかし,大容量化にはまだ時間が必要であり,しばらくはDRAMとの併用が検討されている.新たなコンピューティングアーキテクチャの詳細は,本小特集3「データセンターにおけるコンピューティング技術とそれを支えるネットワーク技術の動向」を御覧頂きたい.
本稿では,データセンターが直面する様々なパラダイムシフトについて概説した.近年研究開発が激化するCPO超小形光トランシーバが実現すれば,従来の「装置間の光接続」から「チップ間の光接続」に概念がシフトし,リソース分離/メモリ中心コンピューティングを大きく押し上げることが可能である.更に,これらの新たな概念の光インタコネクション技術やコンピューティングアーキテクチャは,データセンターの省電力化,大容量化,リソース利用効率/情報処理能力の向上,省スペース化等に大きく寄与する.そして,このような新たな技術をベースとしたエッジ/クラウドコンピューティングでは,Cyber-Physical Systemを高度化し,超スマート社会をもたらすことでこれまでにない新たなサービスが創造されることが期待される.超スマート社会に関しては,本小特集5「B5G/6Gにおけるエッジコンピューティングの役割と超スマート社会への展開」を御覧頂きたい.
(1) 総務省,“Beyond 5G推進戦略―6Gへのロードマップ,” 2020.
(2) Cisco Global Cloud Index: Forecast and Methodology, 2016-2021.
(3) X. Zhou, R. Urata, and H. Liu, “Beyond 1Tb/s datacenter interconnect technology: challenges and solutions,” OFC2019, Tu2F.5, 2019.
(4) A. Singh, J. Ong, A. Agarwal, G. Anderson, A. Armistead, R. Bannon, S. Boving, G. Desai, B. Felderman, P. Germano, A. Kanagala, H. Liu, J. Provost, J. Simmons, E. Tanda, J. Wanderer, U. Hölzle, S. Stuart, and A. Vahdat, “Jupiter rising: A decade of clos topologies and centralized control in Google’s datacenter network,” Commun. ACM, vol.59, no.9, pp.88-97, 2016.
(5) C. Minkenberg, N. Farrington, A. Zilkie, D. Nelson, C. Lai, D. Brunina, J. Byrd, B. Chowdhuri, N. Kucharewski, K. Muth, A. Nagra, G. Rodriguez, D. Rubi, T. Schrans, P. Srinivasan, Y. Wang, C. Yeh, and A. Rickman, “Reimagining datacenter topologies with integrated silicon photonics,” J. Opt. Commun. and Netw., vol.10, no.7, pp.126-139, 2018.
(6) A. Krishnamoorthy, H. Thacker, O. Torudbakken, S. Muller, A. Srinivasan, P. Decker, H. Opheim, J. Cunningham, I. Shubin, X. Zheng, M. Dignum, K. Raj, E. Rongved, and R. Penumatcha, “From chip to cloud: Optical interconnects in engineered systems,” J. Lightwave Technol., vol.35, no.15, pp.3103-3115, 2017.
(7) F. Testa and L. Pavesi, Optical Switching in Next Generation Data Centers, Springer Verlag, New York, 2017.
(8) Y. Mori and K. Sato, “High-port-count optical circuit switches for intra-datacenter networks,” J. Opt. Commun. and Netw., vol.13, no.8, 2021.
(9) OIF CEI-224G.
https://www.oiforum.com/technical-work/hot-topics/common-electrical-i-o-cei-224g/
(10) A. Ghiasi, “Large datacenters interconnect bottlenecks,” Opt. Express, vol.23, no.3, pp.2085-2090, 2015.
(11) 高井厚志,“光トランシーバーのForm Factorの新動向(8)~CPO/NPOと新しいデータセンター” EE Times, Jan. 2022.
(12) OIF CEI-112G.
https://www.oiforum.com/technical-work/hot-topics/common-electrical-interface-cei-112g-2/
(13) Google Cloud.
https://cloud.google.com/tpu/docs/system-architecture-tpu-vm
(14) K. Bergman, “Deeply disaggregated computing systems with embedded photonics,” ARPA-E ENLITENED Program, 2021.
https://arpa-e.energy.gov/sites/default/files/2021-01/DAY1_Bergman_ENLITENED_Phase2_Kickoff.pdf
(15) HPE Blog, “Memory-driven computing explained,” 2017.
https://www.hpe.com/us/en/newsroom/blog-post/2017/05/memory-driven-computing-explained.html
(16) G. Kranz, “Storge class memory (SCM),” TechTarget, Aug. 2021.
https://www.techtarget.com/searchstorage/definition/storage-class-memory
(2022年8月30日受付 2022年9月16日最終受付)

オープンアクセス以外の記事を読みたい方は、以下のリンクより電子情報通信学会の学会誌の購読もしくは学会に入会登録することで読めるようになります。 また、会員になると豊富な豪華特典が付いてきます。
電子情報通信学会 - IEICE会誌はモバイルでお読みいただけます。
電子情報通信学会 - IEICE会誌アプリをダウンロード

![]()