|
|
電子情報通信学会 - IEICE会誌 試し読みサイト
© Copyright IEICE. All rights reserved.
|
|
|
電子情報通信学会 - IEICE会誌 試し読みサイト
© Copyright IEICE. All rights reserved.
|

音声研究専門委員会
音声感情認識
音声感情認識(Speech Emotion Recogntinion)とは,音声から話した人物の感情状態を認識する技術である.感情や情動の伝達や知覚は,人間同士の音声コミュニケーションにおける意思決定や相互理解に重要な役割を果たすとされる(1).このため,人間同士のコミュニケーションの理解や人間と機械との自然なコミュニケーションの実現には,音声感情認識が重要と考えられる.近年では音声感情認識の実用化も進みつつあり,例えばコールセンターにおける顧客満足度の自動推定(2)や,簡易的なメンタルヘルスチェック(3)などに利用されている.
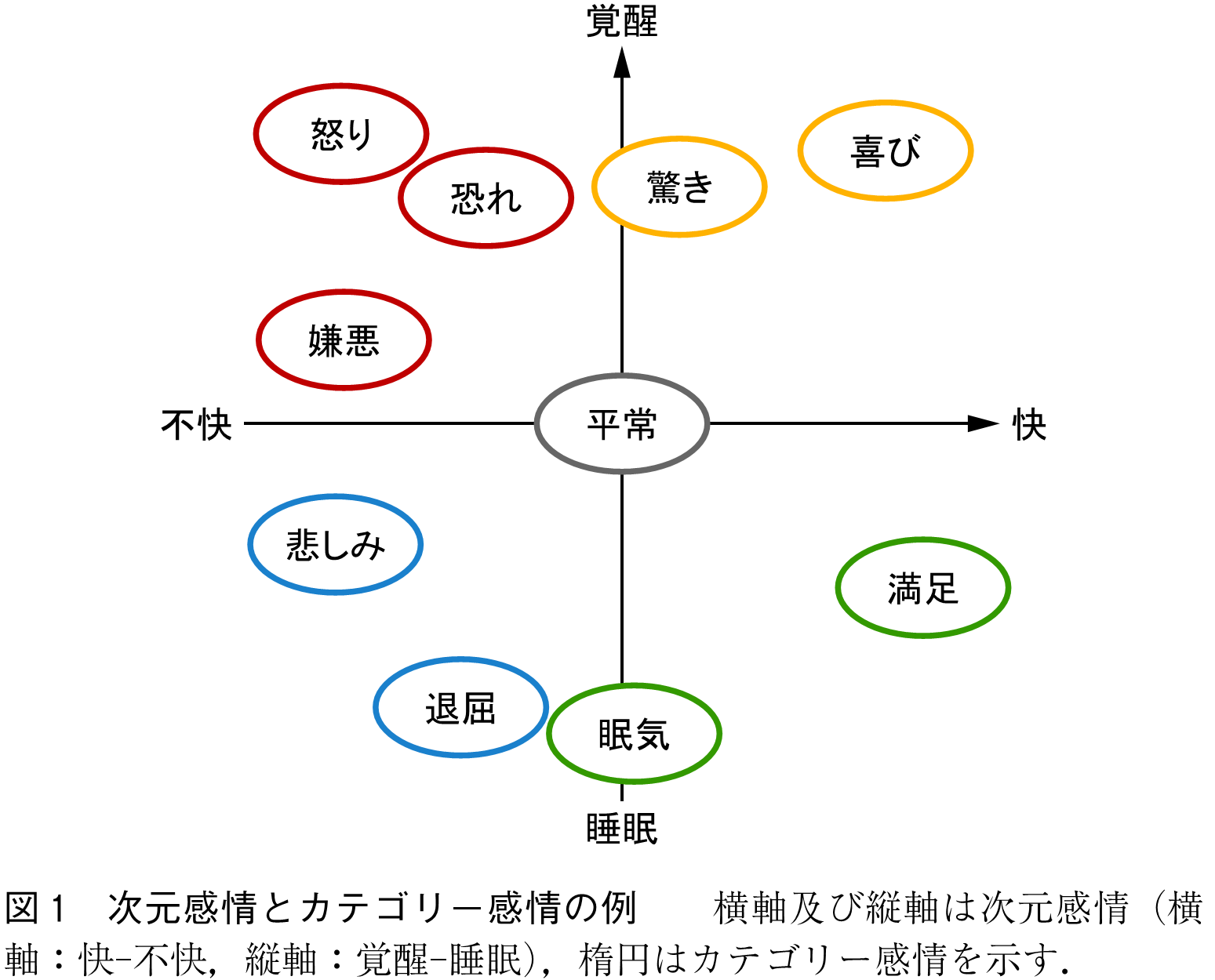
音声感情認識は,カテゴリー感情認識と次元感情認識の二つに大別できる.カテゴリー感情認識は,入力音声が喜び・怒り・悲しみなどの離散的な感情クラスのいずれに該当するかを推定する技術を指す.カテゴリー感情認識は推定結果として得られる感情クラスが人間にとって直観的であるため,人手による正解ラベルの付与が安定しやすく,またほかのアプリケーションにとっても扱いやすい.一方で,認識可能な感情状態の粒度が粗い(例えば,「怒り」という推定結果が「いらつき」か「激怒」か区別できない)という課題もある.次元感情認識は,「快―不快」「覚醒―睡眠」「支配―服従」などの低次元の連続値空間における値を推定する技術である.次元感情認識は感情表現に関するきめ細かな推論が可能であるが,人手による正解ラベルの付与が不安定になりやすいという欠点がある.次元感情とカテゴリー感情の例を図1に示す.
関連分野として,入力音声から感情状態以外の人間の状態を推定する研究も数多く存在する.例えば,アルツハイマー病や大うつ病性障害などの病理状態の推定(4), (5),嘘や皮肉の検出(6)などが挙げられる.音声感情認識も含めたこれらの研究領域はパラ言語情報処理(Paralinguistic Information Processing)とも呼ばれる.
また当然ながら,人間の感情状態は音声だけでなく表情や言葉にも表れる.このため,音声感情認識は表情認識(Facial Expression Recognition)(7)や,テキストに基づくセンチメント分析(Sentiment Analysis)(8),更には脳波などの生体信号に基づく感情認識(9)とも密接に関連している.近年では,映像・音声・テキストなどの複数のモダリティを利用して感情状態を推定する,マルチモーダル感情認識(10)も盛んに研究されている.
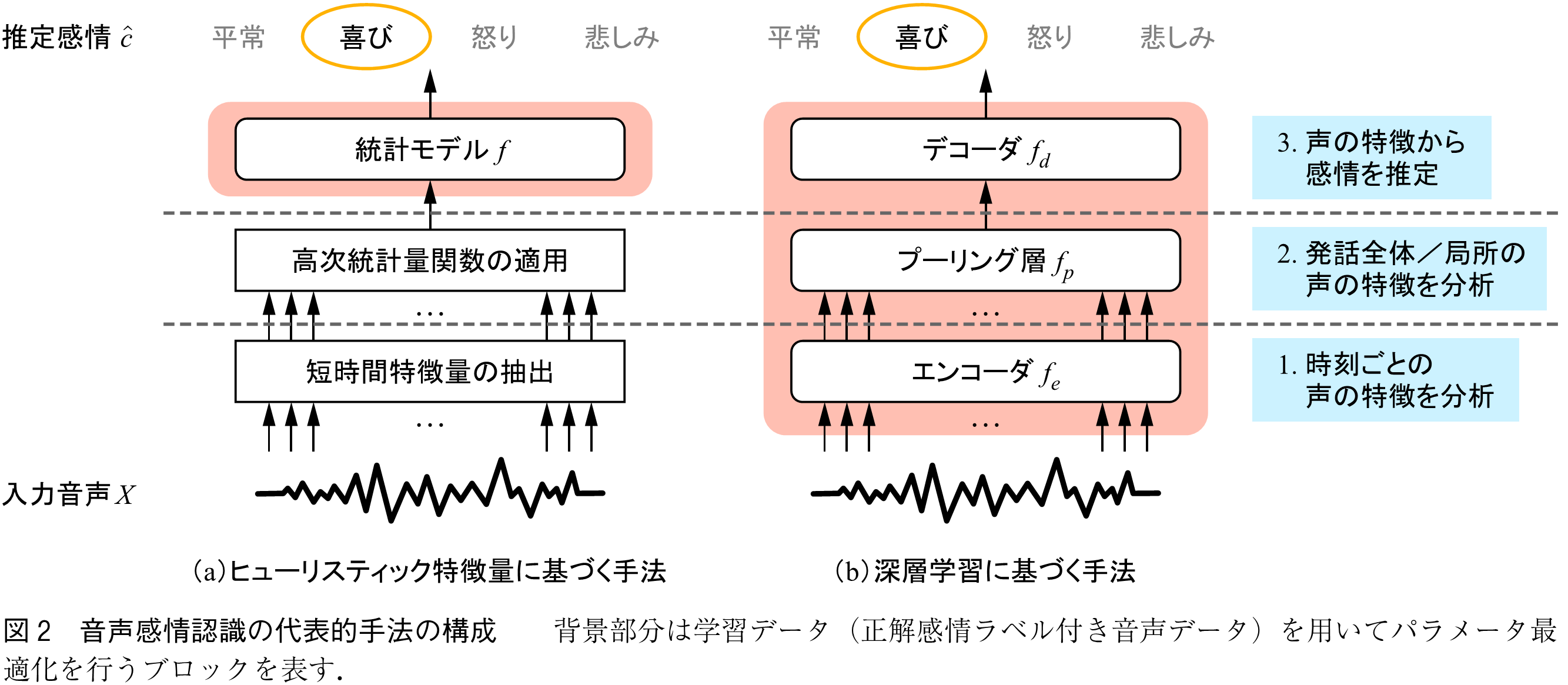
本節では,音声感情認識における二つの代表的手法である,ヒューリスティック特徴量に基づく手法と深層学習に基づく手法を紹介する(図2).以降ではカテゴリー感情認識を例に用いるが,基本的な方法論は次元感情認識でも同一である.
音声感情認識は,ある系列長を持つ入力音声 から正解感情クラス
から正解感情クラス を推定する問題と定式化できる.
を推定する問題と定式化できる.

(1)
ここで, は正解感情クラスの推定値,
は正解感情クラスの推定値, は認識対象の感情クラスの総数,
は認識対象の感情クラスの総数, は認識モデルのパラメータ集合を表す.
は認識モデルのパラメータ集合を表す.
ヒューリスティック特徴量に基づく手法は,感情認識に有効と考えられる特徴量を人手で設計し,その特徴量に基づいて正解感情クラスを推定する手法である.音声が持つ韻律的情報(声の高さ・大きさなどの情報)と感情状態との関連性についてはこれまでに多くの研究が行われており(11), (12),それらの知見を直接的に利用する手法として,初期から盛んに研究が行われた.
この手法では,入力音声からの短時間特徴量(LLDs:Low-Level Descriptors)の抽出と,高次統計量関数(HSFs:High-Level Statistical Functions)の適用によって発話単位特徴量を抽出し,これを入力特徴量として統計的パターン認識モデルにより感情クラスの推定を行う.

(2)
ここで, (·) は短時間特徴量抽出に対応する関数,
(·) は短時間特徴量抽出に対応する関数, (·) は高次統計量関数を表す.短時間特徴量には,数十ミリ秒間隔で算出された基本周波数(声の高さに対応する物理量),信号パワー(声の大きさ),ゼロ交差率(話速),ジッタ(声の震え)などの組合せが用いられる.高次統計量関数は,短時間特徴量の発話全体または始終端区間での平均,分散,最大値,最小値,四分位数などの関数が用いられる.上記により得られた数百~数千次元の発話単位特徴量を入力とし,ニューラルネットワークや決定木などの統計モデルを用いて感情クラスを推定する.
(·) は高次統計量関数を表す.短時間特徴量には,数十ミリ秒間隔で算出された基本周波数(声の高さに対応する物理量),信号パワー(声の大きさ),ゼロ交差率(話速),ジッタ(声の震え)などの組合せが用いられる.高次統計量関数は,短時間特徴量の発話全体または始終端区間での平均,分散,最大値,最小値,四分位数などの関数が用いられる.上記により得られた数百~数千次元の発話単位特徴量を入力とし,ニューラルネットワークや決定木などの統計モデルを用いて感情クラスを推定する.
ヒューリスティック特徴量に基づく手法の最大のメリットは,仕組みが単純であるために手法改良や内部動作の分析が容易である点である.一方で,この手法は音声感情認識精度がそれほど高くなかった.これは,感情表現は発話者や前後の文脈などに依存するために膨大なパターンを持つ一方で,そのような多様な感情表現に対して最適な特徴量を人手で設計することが困難であったためである.
深層学習に基づく手法では,人手による特徴量設計を行わず,特徴量抽出からクラス分類まで全てをニューラルネットワークで行う.

(3)
ここで, (·),
(·), (·),
(·), (·) 及び
(·) 及び ,
, ,
, はそれぞれエンコーダ,プーリング層,デコーダの射影関数及びパラメータ集合を示す.エンコーダは入力音声からの短時間特徴量の抽出,プーリング層は短時間特徴量から発話単位特徴量への変換,デコーダは発話単位特徴量に基づく感情クラス推定の機能に対応する.
はそれぞれエンコーダ,プーリング層,デコーダの射影関数及びパラメータ集合を示す.エンコーダは入力音声からの短時間特徴量の抽出,プーリング層は短時間特徴量から発話単位特徴量への変換,デコーダは発話単位特徴量に基づく感情クラス推定の機能に対応する. ,
, ,
, はランダムに初期化されたのち,学習データを用いて同時最適化される.深層学習に基づく手法では,学習データに対して最も誤りが小さくなるように各ブロックの最適化が行われる.すなわち,過去の知見を利用することなく,学習データに対して最適な特徴抽出器や分類器を得ることができる.深層学習に基づく手法の導入により,音声感情認識の認識精度は大きく向上した(13), (14).一方で,ヒューリスティック特徴量に基づく手法に比べてより多くの学習データを必要とすることや,モデル内部の挙動解析が難しく,精度向上原因や推論根拠が分かりづらいという課題もある.
はランダムに初期化されたのち,学習データを用いて同時最適化される.深層学習に基づく手法では,学習データに対して最も誤りが小さくなるように各ブロックの最適化が行われる.すなわち,過去の知見を利用することなく,学習データに対して最適な特徴抽出器や分類器を得ることができる.深層学習に基づく手法の導入により,音声感情認識の認識精度は大きく向上した(13), (14).一方で,ヒューリスティック特徴量に基づく手法に比べてより多くの学習データを必要とすることや,モデル内部の挙動解析が難しく,精度向上原因や推論根拠が分かりづらいという課題もある.
近年では,自己教師あり学習(SSL:Self-supervised Learning)モデルをエンコーダ及びその初期パラメータ として認識モデルを学習する,自己教師あり学習モデルに基づく手法が主流となっている(15).自己教師あり学習モデルは,膨大な音声データを用いて入力音声のうちマスクされた部分区間を推定するタスクを学習したモデルであり,発音や話者性,話し方などの音声に関する特徴の知識を獲得済みであるとされる(16).このため,少量の感情ラベル付き音声データからであっても入力音声と正解感情との関係性を効率よく学習でき,高精度な音声感情認識モデルが得られやすい.
として認識モデルを学習する,自己教師あり学習モデルに基づく手法が主流となっている(15).自己教師あり学習モデルは,膨大な音声データを用いて入力音声のうちマスクされた部分区間を推定するタスクを学習したモデルであり,発音や話者性,話し方などの音声に関する特徴の知識を獲得済みであるとされる(16).このため,少量の感情ラベル付き音声データからであっても入力音声と正解感情との関係性を効率よく学習でき,高精度な音声感情認識モデルが得られやすい.
音声感情認識の研究トピックは,上記に示した認識モデルの改良だけでなく,言語的情報や対話文脈の活用,言語に依存しない感情認識(クロスリンガル感情認識)の実現,特定の聴取者の感情知覚の再現など様々なものが存在する.これらの詳細については拙著(17)を参照頂きたい.
最後に,音声感情認識に関する重要なトピックとして,AIの法規制との関連について述べておきたい.欧州のArtificial Intelligence Act(AI規制法)(注1)をはじめとしたAIに関する法では,音声感情認識をはじめとした感情認識技術は名指しで規制対象とされることが多い.例えばAI規制法では,職場や教育現場での感情認識AIの利用は原則禁止,その他の場面でも感情認識AIは高リスクと明言されている.この主な根拠として,(1)感情表現は文化や状況,更には個人によっても異なるため,感情認識技術の科学的根拠には懸念があること,(2)感情認識は特定の集団または人物に対して差別的な結果をもたらす可能性があり,権利と自由を侵害する恐れがあること,が挙げられている.これらの背景もあり,近年では上記課題を解決するための推論バイアスの低減(18)などの新たな研究も増えつつある.今後は推論精度の向上だけでなく,科学的根拠の提示や公平性の担保など,多様な側面から音声感情認識の発展が求められていると言える.
(1) 森 大毅,前川喜久雄,粕谷英樹,音声は何を伝えているか-感情・パラ言語情報・個人性の音声科学-.コロナ社,2014.
(2) A. Ando, R. Masumura, H. Kamiyama, S. Kobashikawa, Y. Aono, and T. Toda, “Customer satisfaction estimation in contact center calls based on a hierarchical multi-task model,” IEEE/ACM Trans. on Audio, Speech, and Lang. Proc., vol.28, pp.715-728, 2020.
(3) M. Egger, M. Ley, and S. Hanke, “Emotion recognition from physiological signal analysis: A review,” Electronic Notes in Theoretical Computer Science, vol.343, pp.35-55, 2019.
(4) F. Bertini, D. Allevi, G. Lutero, L. Calzà, and D. Montesi, “An automatic Alzheimerʼs disease classifier based on spontaneous spoken English,” Computer Speech & Language, vol. 72, 101298, 2022.
https://www.sciencedirect.com/science/article/abs/pii/S0885230821000991(2025年8月確認)
(5) W. Wu, C. Zhang, and P. C. Woodland, “Self-supervised representations in speech-based depression detection,” Proc. ICASSP, pp.1-5, 2023.
(6) J. Hirschberg, S. Benus, J. M. Brenier, F. Enos, S. Friedman, S. Gilman, C. Girand, M. Graciarena, A. Kathol, L. Michaelis, B. L. Pellom, E. Shriberg, and A. Stolcke, “Distinguishing deceptive from non-deceptive speech,” Proc. Interspeech, pp.1833-1836, 2005.
(7) T. Kopalidis, V. Solachidis, N. Vretos, and P. Daras, “Advances in facial expression recognition: A survey of methods, benchmarks, models, and datasets,” Information, vol. 15, no. 3, 135, 2024.
https://www.mdpi.com/2078-2489/15/3/135(2025年8月確認)
(8) M. Wankhade, A. C. S. Rao, and C. Kulkarni, “A survey on sentiment analysis methods, applications, and challenges,”Artificial Intelligence Review, vol.55, pp.5731-5780, 2022.
(9) N. A. N. Azar, N. Cavus, P. Esmaili, B. Sekeroglu, and S. Aşır, “Detecting emotions through EEG signals based on modified convolutional fuzzy neural network,” Scientific Reports, vol. 14, 10371, 2024.
https://www.nature.com/articles/s41598-024-60977-9(2025年8月確認)
(10) X. Wang, S. Zhao, H. Sun, H. Wang, J. Zhou, and Y. Qin, “Enhancing multimodal emotion recognition through multi-granularity cross-modal alignment,” Proc. ICASSP, pp.1-5, 2025.
(11) A. Batliner, K. Fischer, R. Huber, J. Spilker, and E. Nöth, “Desperately seeking emotions or: Actors, wizards, and human beings,” Proc. ITRW on Speech and Emotion, pp.195-200, 2000.
(12) N. Amir and E. Globerson, “On the role of pitch in perception of emotional speech,” Proc. Speech Prosody, pp.154-158, 2014.
(13) G. Trigeorgis, F. Ringeval, R. Brueckner, E. Marchi, M. A. Nicolaou, B. Schuller, and S. Zafeiriou, “Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network,” Proc. ICASSP, pp.5200-5204, 2016.
(14) G. Ramet, P. N. Garner, M. Baeriswyl, and A. Lazaridis, “Context-aware attention mechanism for speech emotion recognition,” Proc. SLT, pp.126-131, 2018.
(15) J. Shor, A. Jansen, W. Han, D. Park, and Y. Zhang, “Universal paralinguistic speech representations using self-supervised conformers,” Proc. ICASSP, pp.3169-3173, 2022.
(16) S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y. Qian, Y. Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Proc., vol.16, no.6, pp.1505-1518, 2022.
(17) 安藤厚志,“音声感情認識の技術動向,”日本音響学会誌,vol.79, no.1, pp.72-79, 2023.
(18) W.-S. Chien and C.-C. Lee, “An investigation of group versus individual fairness in perceptually fair speech emotion recognition,” Proc. Interspeech, pp.3205-3209, 2024.
(2025年6月20日受付)
(注1) https://eur-lex.europa.eu/eli/reg/2024/1689/oj(2025年6月確認)
オープンアクセス以外の記事を読みたい方は、以下のリンクより電子情報通信学会の学会誌の購読もしくは学会に入会登録することで読めるようになります。 また、会員になると豊富な豪華特典が付いてきます。
電子情報通信学会 - IEICE会誌はモバイルでお読みいただけます。
電子情報通信学会 - IEICE会誌アプリをダウンロード

![]()