|
|
電子情報通信学会 - IEICE会誌 試し読みサイト
© Copyright IEICE. All rights reserved.
|
|
|
電子情報通信学会 - IEICE会誌 試し読みサイト
© Copyright IEICE. All rights reserved.
|

筆者は以前,本会の「思考と言語研究専門委員会」の幹事を務めていた.その縁もあり,研究専門委員会の委員長からお声掛け頂き,本特集記事を執筆する機会を得た.思考と言語研究専門委員会では,人間の知能に深く関わる思考及び言語に関するテーマを主に扱い研究会活動を行っており,筆者はその工学的応用である自然言語処理の研究を行っている.本稿では,自然言語処理分野の中で近年筆者が特に関心を持っている評判分析と呼ばれる分野について述べたいと思う.
本稿では,特集企画の趣旨に沿って,まず現在の評判分析研究の概要,要素技術及び技術的課題について説明する.その後,遠い未来の社会において,本分野の技術がどのように活用されるかについての個人的な予測・希望を楽観的に述べる.
評判分析(sentiment analysis)とは,文字どおり,評判を分析することであるが,本稿では専ら自然言語処理(NLP: Natural Language Processing)に関する話題を扱う.自然言語処理分野における評判分析とは,テキストデータ中の評判を解析することである.幾つかの解析課題があるが,最も中心的な課題はテキストに書かれている評判が肯定的(positive sentiment)であるか否定的(negative sentiment)であるかを自動分類する課題(以下,評判分類と呼ぶ)である.例えば,週末にA氏がワインを片手に映画鑑賞をし,その感想としてソーシャルメディアへ以下のような投稿をしたとしよう.
・ 今日は赤ワインにしました.20年物でとってもまろやか.映画の方はストーリーが古めでありきたりでした.ではまた来週.
この投稿に対して,評判分類では以下のような出力を行うことが期待される.
・ 今日は赤ワインにしました.
・ 【positive】20年物でとってもまろやか.
・ 【negative】映画の方はストーリーが古めでありきたりでした.
・ ではまた来週.
評判分析はソーシャルメディアの普及とともに発展したこともあり,先例のように,ソーシャルメディアを中心としたWebサービスに投稿されたテキストを処理対象とすることが多い.例えば,商品レビュー(商品を使用したユーザの感想)を使った評判分析システムはよくある応用例である.このようなシステムでは商品レビューを解析することで商品の評判の良し悪しを自動推定する.推定結果は,実際の商品ユーザの生の声が反映されていると考えられ,商品の購入を検討しているB氏がその商品を購入するかどうかの手掛かりとなったり,商品製造者にフィードバックすることで商品の改善に用いられたりする.また,標準的な評判分析システムでは,解析対象テキストを参照することで,評判の良し悪しと同時に付加情報として,その根拠(例:「まろやか」)や,何が評価されているか(例:「ストーリー」)を併せて出力できる.これは売上数などのような定量的なデータからは獲得することができない情報であり,NLP技術に基づく言語データを使った評判分析の一つの利点と言える.
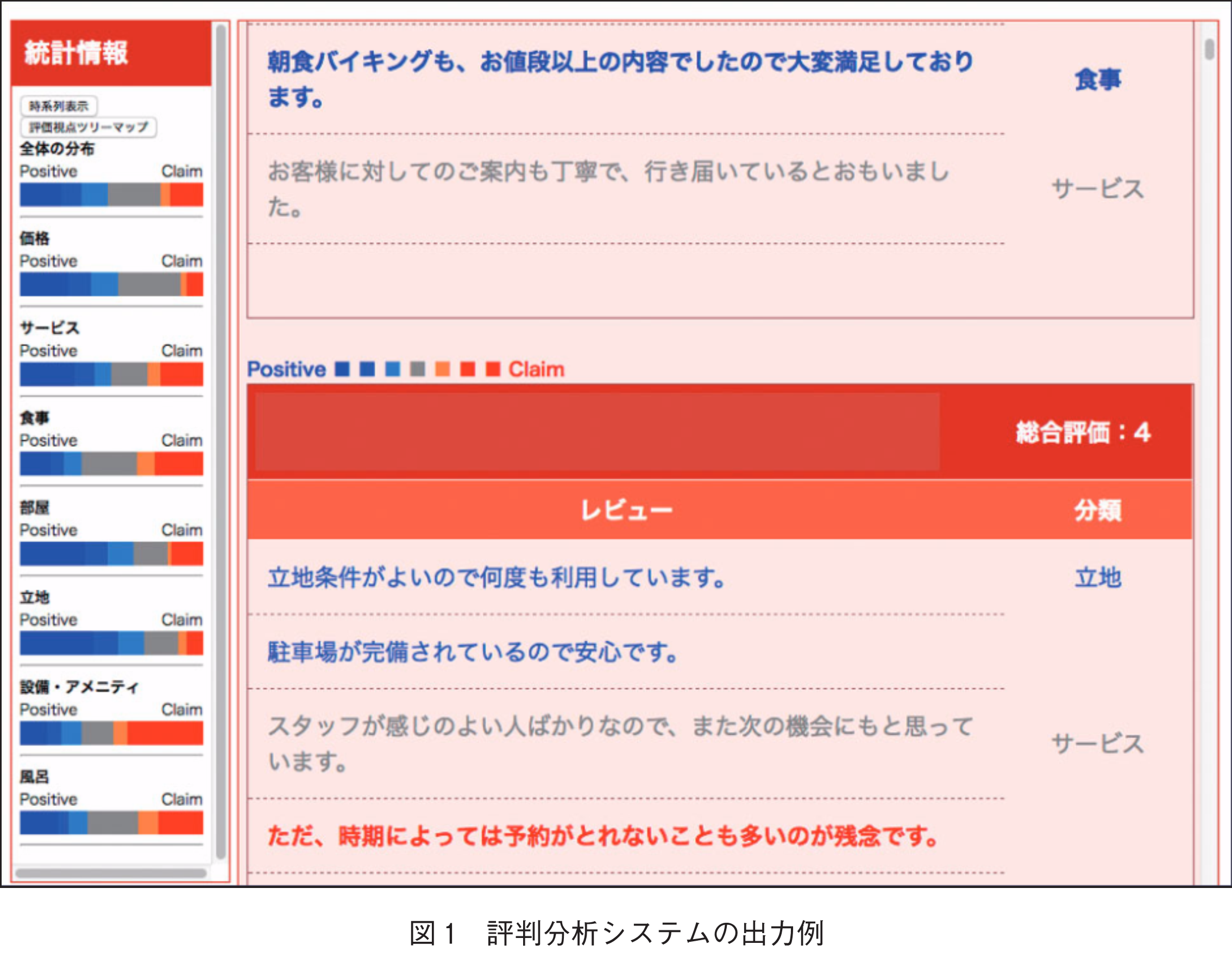
評判分析システムの例として,筆者の研究室で開発を進めているシステムのスクリーンショットを図1に示す.このシステムでは,宿泊施設予約サイト「楽天トラベル」に投稿された宿泊レビュー(注1)を利用して宿泊施設の評判を解析している.図の右側は各レビューの解析結果を示し,図の左側は全てのレビューの解析結果の要約である.評判の良し悪しが色情報で示されており,色の濃淡でその強さが示されている.
この分野の最初期に,テキストに書かれている評判を自動分類する課題に取り組んだのがTurney(1)である.ここではTurneyの手法(以下,Turney法)の概要を紹介する.この手法は,共起情報に基づく素朴な手法であり,実現にあたって何ら言語リソースを準備する必要がない.そのため,汎用性や拡張性が高く,提案から10年以上が経過した現在においても幅広く活用される基本的な手法である.なお,研究開発の主流は,NLP分野の他テーマと同様,教師ありデータを用いた機械学習に基づく手法であり,毎年数多くの論文が発表されている.機械学習に基づく評判分類の手法については,例えば,文献(2)に丁寧な解説がある.
さて,Turney法は,入力テキストに含まれるフレーズに対してSemantic Orientation(SO)と呼ばれるスコアを計算し,このスコアに基づいて分類を実行する.具体的な手続きは以下のとおりである.
(1) 入力テキスト中のフレーズを抽出する.
(2) フレーズのSOスコアを計算する.
(3) SOスコアの平均値に基づいて分類する.
[フレーズの抽出]
まず,入力テキストから評判分類に影響を与えると考えられるフレーズを抽出する.具体的には「形容詞 名詞」のように,形容詞を中心とした特定の品詞を含む2語以上の単語列を抽出している.これは,人の意見は形容詞に反映される(3)という先行研究の知見に基づいている.
[SOスコアの計算]
NLPでは,単語が持つ意味に関してしばしば「同じ文脈に共によく現れる単語は意味的に関連している」という仮定を置く.この仮定に従うなら,良い評判を表す単語と強く共起するフレーズはやはり良い評判を表しやすく,逆に,悪い評判を表す単語と強く共起するフレーズはやはり悪い評判を表しやすいと言える.Turneyは,この考え方に基づいて,先のステップで抽出したフレーズに対して以下の式で計算されるSOスコアを定義した.

(1)
ここで, は単語
は単語 と単語
と単語 の共起の強さを表す尺度である.SOスコアは,対象フレーズ
の共起の強さを表す尺度である.SOスコアは,対象フレーズ がpoorよりexcellentと強く共起すれば正に大きな値となり,逆に,excellentよりpoorと強く共起すれば負に大きな値となる.
がpoorよりexcellentと強く共起すれば正に大きな値となり,逆に,excellentよりpoorと強く共起すれば負に大きな値となる.
一般に, は次式で計算される.
は次式で計算される.

(2)
ここで, ,
, は各単語の生起確率を表し,
は各単語の生起確率を表し, は両単語の共起確率を表す.上式の値を求めるにはコーパス(用語)における各単語の出現頻度及び共起頻度を参照することになるが,文献(1)ではその代わりにWeb検索のヒット件数を用いている.ヒット件数をhits( )とし,上記の二つの式をまとめて書くと,最終的なSOスコアの計算式は以下となる.
は両単語の共起確率を表す.上式の値を求めるにはコーパス(用語)における各単語の出現頻度及び共起頻度を参照することになるが,文献(1)ではその代わりにWeb検索のヒット件数を用いている.ヒット件数をhits( )とし,上記の二つの式をまとめて書くと,最終的なSOスコアの計算式は以下となる.


(3)
[平均値に基づく分類]
前のステップで得られたSOスコアの平均値を求める.そして,平均値の符号を参照し,符号が正であれば良い評判,負であれば悪い評判と判定する.直感的には,良い(悪い)評判を表しやすい単語を多く含むテキストには良い(悪い)評判が書かれていると考えられる.言い換えると,テキストに書かれた評判は,評判の良し悪しを表す単語の多数決で決定できると考えられる.Turney法はこの直感の一つの実装形であり,単純な多数決ではなく,SOスコアという重みを考慮した重み付多数決を行っていると解釈できる.
評判分析あるいはその中心的課題である評判分類の性能を向上させるために,現在進行形で様々な検討が進められている.以下では,今後更なる発展が期待される話題を幾つか紹介する.
評判分類は古くからあるNLP課題の一つである文書分類(4)の一種であり,同じように問題の定式化が可能である.論文や特許をその内容に従って分類するトピック分類では文書内の単語の情報を特徴量として使用する.評判分類も同様であるが,評判を表しやすい単語が特に重要な特徴量となる.評判分類では更に,Sentiment shifterの扱いに注意を向けなければならない.Sentiment shifterとは,単語が表す評判情報を変更させる(通常は逆転させる)働きを持つ単語であり,「ない」などの否定辞がその代表と言える.Sentiment shifterの例を以下に示す.
・ おいしくない
この例の場合,“おいしい”という単語自体は良い評判を表すが,否定辞によって全体として悪い評判を表す表現となっている.このようにSentiment shifterの有無は評判の内容に直結するため,特に長い文では否定辞のスコープ(用語)を正確に把握し(5),その情報を分類モデルで適切に取り扱う必要がある.
次に,評判分析の処理対象となるテキストの特性に目を向けてみる.冒頭で述べたように,評判分析の主な処理対象はソーシャルメディアを流れるテキストであるが,このようなテキストは表記の多様性が生じやすい.例えば,以下の例はいずれも食べた料理がおいしかったことを書きとどめたものであるが,表記が様々である.
・ とっても美味しい
・ とってもおいしい
・ とっても美味しー
・ とってもおいし~い
理想的には,これらの例文は全て同じ内容を表しているものとして処理したい(注2).そのためには,単語分割を行う形態素解析レベルでこの表記の多様性を吸収したり(6),単語情報だけでなく文字情報(7)や,分散表現(8),(9)のように単語の意味を何らかの形で抽象化させた情報を考慮するといった対策が求められる.
また,領域依存性の問題もある.現在のところ,評判分類をはじめとする評判分析の各解析モデルはあらかじめ定めた領域の商品に関する評判しか適切に処理できない.そのため,領域ごとの解析モデルを構築しなければならない.(冒頭の例であれば,ワインと映画それぞれの解析モデルが必要である.)この領域依存性問題への対策として,教師ありデータを共有するための領域適応(10)の検討が進められている.
最後に,遠い未来の社会において,評判分析の技術がどのように活用されているかについての私見を述べたい.本特集企画は「100年」がキーワードになっており,本稿でも100年後の未来を語るべきかもしれない.ただ,筆者の力量では100年後の自然言語処理界隈への想像が及ばなかったため,以下では筆者が隠居しているであろう頃の未来(注3)という設定で語ってみたい.
さて,評判分析の技術は主観情報に対する言語処理技術と位置付けられることがある.主観情報と言語処理という二つの観点から見えてくるものとして感情認識があると筆者は考えている.ただし,音声や顔の表情,ジェスチャといったノンバーバルな情報に基づく感情認識は現在でも商業化されるレベルにあるので,ここでは言語情報に基づく感情認識に絞って考えてみたい.
現在の状況を簡単に整理すると,現在の評判分析はソーシャルメディア上のテキストを処理対象として評判の良し悪しを解析している.これに対して筆者が想像する言語情報に基づく未来の感情認識は以下である.
まず,認識の対象が評判から感情に変わるが,感情カテゴリーは思想的背景に応じて見解が異なることから(11),深入りしない.快・不快や喜怒哀楽といったカテゴリーを想定しておけば十分だろう.評判と感情そのものの違いについては注意を要するがこれについては後述する.
次に,処理する言語データの発生源についてはソーシャルメディアから大きな広がりを見せる.すなわち,現在はA氏がソーシャルメディア上の読み手へ向けた投稿行為を行うことで処理対象となる言語データが得られるが,未来では音声由来の言語データが主になるだろう.A氏はウェアラブルな音声認識器を装着し発話が常時記録され,言語データとして蓄積される.ここで,対話エージェントの存在が鍵となる役割を果たす.日常生活の中でA氏の感情は様々変化するだろうが,その感情が言語化されて表出するとは限らない.A氏はワインがおいしいと感じ快な感情を感じていたとして,下記の発話のケースaの状態である(図2も参照).つまり,受動的な音声認識だけでは仕掛けが十分でない.
・ ケースa:
・ ケースb:おいしい
・ ケースc:またこれを飲もう
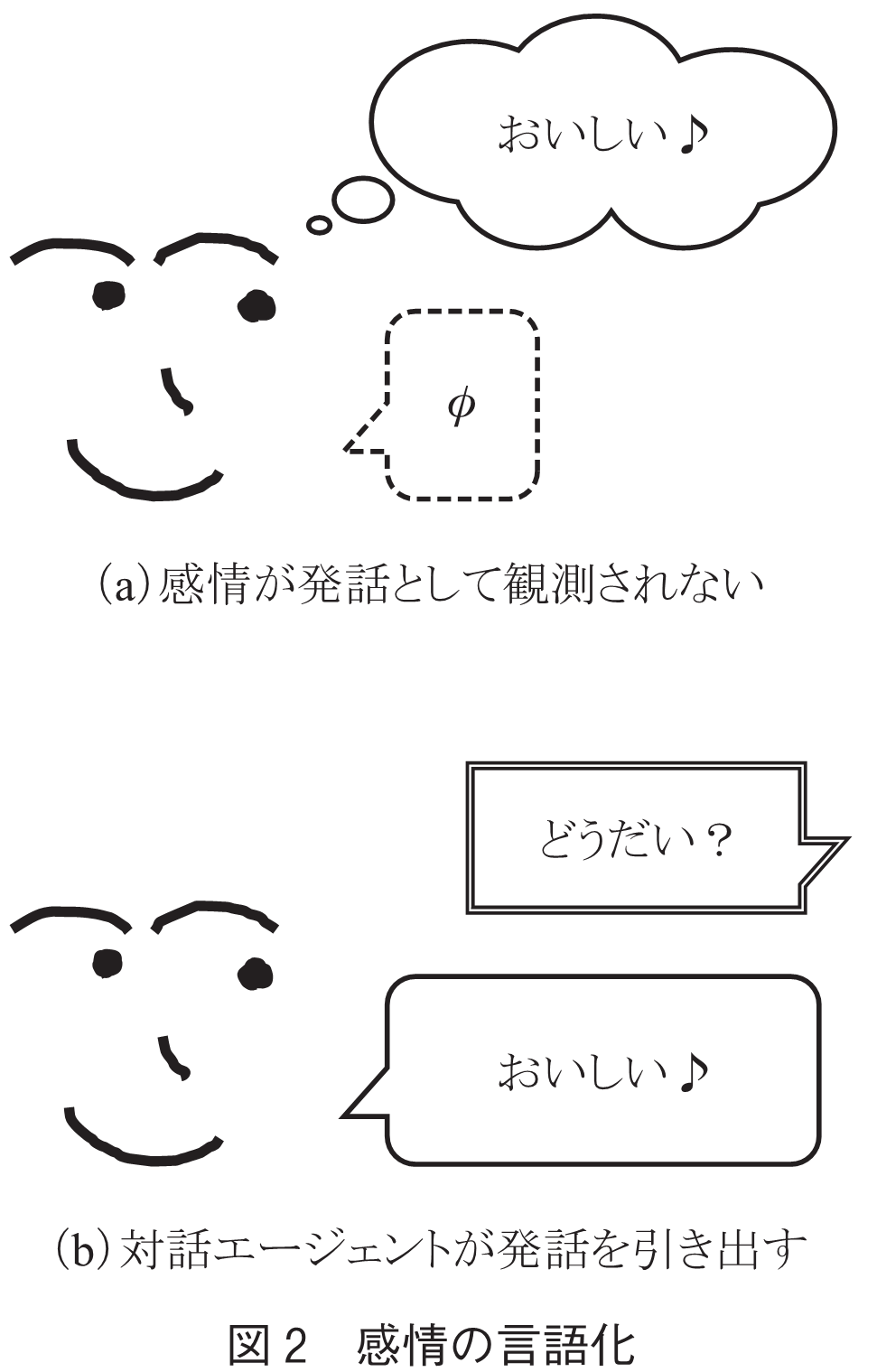
そこで,対話エージェントを導入する.対話エージェントがA氏と対話することで能動的にA氏の感情状態が陽に分かる言語データを獲得する(ケースb).ここに思考を踏まえて生成される評判とそうでない感情の処理方法の違いが生まれる.更に,対話の流れによってはケースcのような発話も考えられる.この場合は,エージェントを適切に制御してケースbの発話を導くか,ケースcの発話に陰に含まれるA氏の(快な)感情を認識することが求められる.現在の研究領域で言えば,前者は対話処理の領域が深く関与し,後者は人間の常識や世界知識を踏まえた言語理解であり,知識獲得の研究領域が深く関与する.いずれも活発な議論が交わされているところであり企画趣旨にのっとり楽観的に進展を待ちたい.
倫理的あるいは社会的な観点からの制約はあるかもしれないが,技術的な観点から言えば,上記のような環境は遠い未来に十分到達可能だろう.当然のことながら,感情認識機能を備えた知的インタフェースは我々の生活を多角的に支援してくれるはずである.ぜひ,そのような環境で隠居したいものである.
(1) P.D. Turney, “Thumbs up? thumbs down? semantic orientation applied to unsupervised classification of reviews,” Proc. the 40th Annual Meeting of the Association for Computational Linguistics, pp.417-424, 2002.
(2) ダヌシカボレガラ,岡崎直観,前原貴憲.ウェブデータの機械学習,講談社,2016.
(3) V. Hatzivassiloglou and K.R. McKeown, “Predicting the semantic orientation of adjectives,” Proc. the 35th Annual Meeting of the Association for Computational Linguistics,” pp.174-181, 1997.
(4) F. Sebastiani, “Machine learning in automated text categorization,” ACM Comput. Surv., vol.34, no.1, pp.1-47, 2002.
(5) I.G. Councill, R. McDonald, and L. Velikovich, “What’s great and what’s not: learning to classify the scope of negation for improved sentiment analysis,” Proc. the Workshop on Negation and Speculation in Natural Language Processing, pp.51-59, 2010.
(6) 笹野遼平,黒橋禎夫,奥村 学,“日本語形態素解析における未知語処理の一手法―既知語から派生した表記と未知オノマトペの処理―,”自然言語処理,vol.21, no.6, pp.1183-1205, 2014.
(7) C. dos Santos and M. Gatti, “Deep convolutional neural networks for sentiment analysis of short texts,” Proc. the 25th International Conference on Computational Linguistics, pp.69-78, 2014.
(8) Q. Le and T. Mikolov, “Distributed representations of sentences and documents,” Proc. the International Conference on Machine Learning, pp.1188-1196, 2014.
(9) T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean, “Distributed representations of phrases and their compositionality,” Proc. Advances in neural information processing systems, pp.3111-3119, 2013.
(10) S.J. Pan, X. Ni, J.-T. Sun, Q. Yang, and Z. Chen, “Cross-domain sentiment classification via spectral feature alignment,” Proc. the 19th International World Wide Web Conference, pp.751-760, 2010.
(11) ランドルフ・コーネリアス,感情の科学,誠信書房,1999.
(平成29年1月25日受付 平成29年2月10日最終受付)

(注1) このレビューデータは大学や公的研究機関での研究向けに公開されている.詳細は以下のサイトを参照されたい.http://rit.rakuten.co.jp/opendataj.html
(注2) 書き手の立場としては,食べて感じたおいしさのニュアンスの違いを表現している可能性もあるが….
(注3) すなわち,およそ四半世紀後の未来.
■ 用 語 解 説
続きを読みたい方は、以下のリンクより電子情報通信学会の学会誌の購読もしくは学会に入会登録することで読めるようになります。 また、会員になると豊富な豪華特典が付いてきます。
電子情報通信学会 - IEICE会誌はモバイルでお読みいただけます。
電子情報通信学会 - IEICE会誌アプリをダウンロード

![]()