|
|
電子情報通信学会 - IEICE会誌 試し読みサイト
© Copyright IEICE. All rights reserved.
|
|
|
電子情報通信学会 - IEICE会誌 試し読みサイト
© Copyright IEICE. All rights reserved.
|

リコンフィギャラブルシステム研究専門委員会
半導体集積回路の成長と進化
――CPU,GPU,FPGA――
スマートフォンやタブレット端末など,私たちの身の回りには多くの電子機器があふれている.これらの電子機器を動かしているIC(Integrated Circuit,集積回路)は,シリコンに代表される半導体材料を使って作られており,電気信号を制御,増幅,変換する役割を持っている.特に大規模なICはVLSI(Very Large Scale Integrated Circuit,超大規模集積回路)とも呼ばれることもある.このため,ICやVLSIは半導体集積回路とも称される.
代表的な半導体集積回路として以下などが挙げられる.
・CPU(Central Processing Unit,中央演算装置)
・GPU(Graphic Processing Unit,画像処理装置)
・FPGA(Field Programmable Gate Array)
CPUは,計算機の中核を担う処理装置であり,多種多様な計算や操作を行う.GPUは,大量のデータを同時に処理する能力に優れており,特にグラフィックスや映像の処理,機械学習などで力を発揮する.FPGAは,使用者が目的に応じて再プログラム可能な集積回路で,特定の用途に最適化された集積回路をプログラムにより実現できる.最適化することで,効率的かつ低遅延な処理が可能になる.これらの集積回路は,それぞれの特性を生かして,様々な分野で重要な役割を果たしている.
集積回路の成長に関して有名な法則がある.その提案は1965年まで遡る.米国インテル社の創業者の一人であるゴードン・ムーア氏は,集積回路で使用されるトランジスタ数が約2年ごとに2倍になると予測した(1).その後,1971年にインテル社から一般向けプロセッサ4004が発売された.このプロセッサには約2,300個のトランジスタが使用されていた.半世紀後の2021年には,インテル社の高速演算用GPUであるPonte Vecchioが約1,000億個のトランジスタを使用していることから,ムーアの法則は現在も続いていることが分かる.
集積回路技術とその進歩については「知識の森・10群集積回路編」で確認できる.
情報機器の能力を議論する際,演算時間の長短が最も重要な指標である.これは,1950年代に登場したメインフレームと呼ばれる大形計算機の時代から変わらない.
図1に,文献(2)のデータを基に作成したこの50年間の集積回路の成長を示す.図1の指標SpecINT(整数演算の処理速度)のように,単位時間当りに処理する命令数は処理性能の一つの基準となる.加えて処理性能が同じでも,消費電力が小さければ電力効率が優れていると言える.
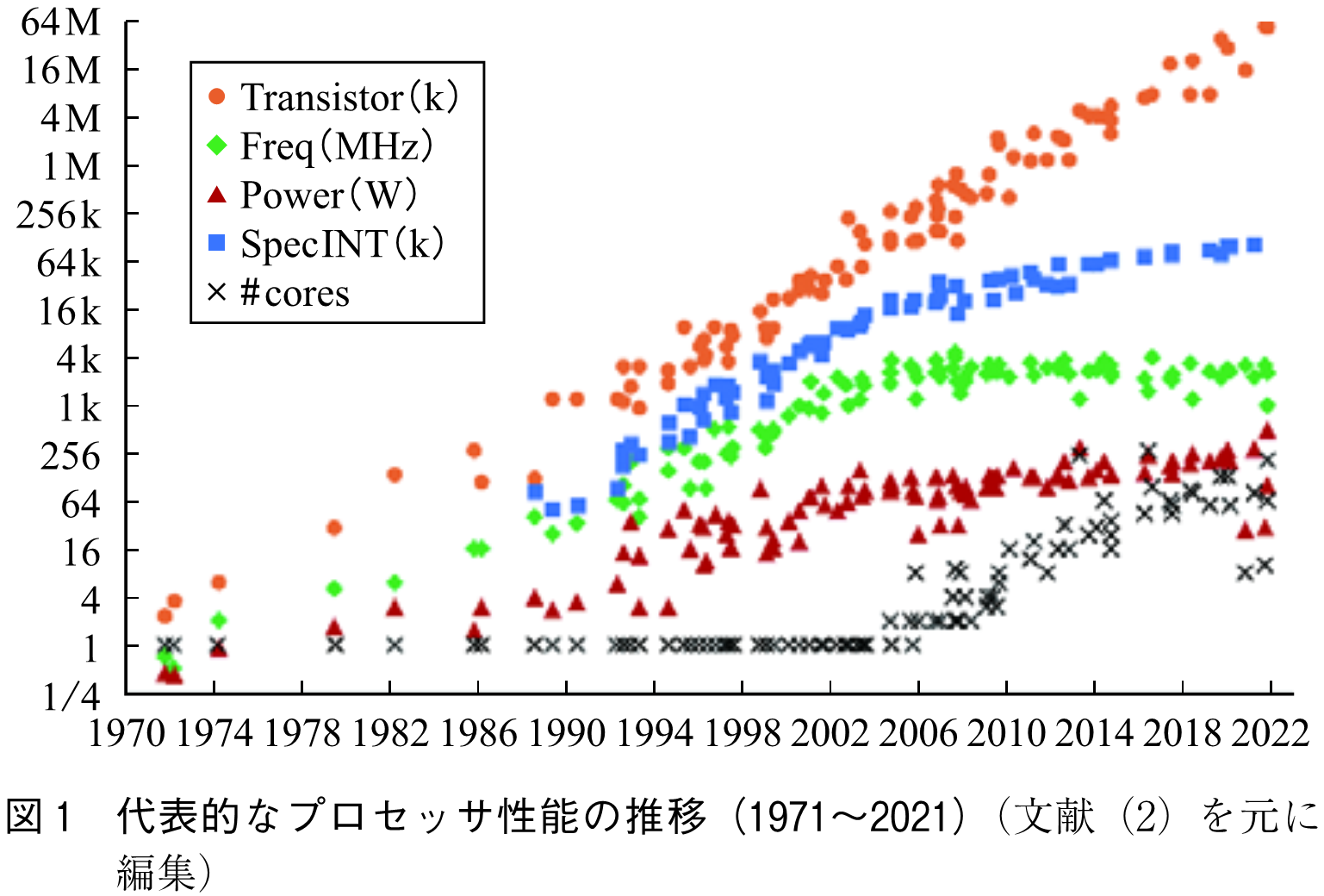
また,ムーアの法則に従いトランジスタ数が増えている様子は●印で示されている.横軸に2目盛進む(4年)と縦軸に1目盛(2倍)以上の成長が続いていることが分かる.
大形計算機の中心的な処理装置として機能したのがCPUである.1970年代に入ると,半導体製造技術の向上により,集積回路当りのトランジスタ数が1,000個を超え,CPU及び入出力の機能を単一の集積回路で実現できるようになった.1971年に登場したIntel社の4004はその先駆けである.この一体化によりMPU(Microprocessor Unit)とも呼ばれる.この時代にPC(Personal Computer,個人向け電子計算機)の基礎が築かれ,計算機の小形化が進んだ.
集積回路当りのトランジスタ数が10万を超えると,演算処理の汎用化と効率化に焦点が当てられるようになった.大形計算機向けに複雑な命令セットを持つCISC(Complex Instruction Set Computer)に対し,シンプルで効率的な命令セットアーキテクチャのRISC(Reduced Instruction Set Computer)が提案された.2015年に登場したRISC-V(3)のRISCはここに由来する.なお,この時代の集積回路の動作周波数は数MHzから数十MHzであった.CISCとRISCに興味を持った方は「知識の森・6群4編7章命令パイプライン」を参照されたい.
この時代には,試作用の集積回路や集積回路同士をつなげる集積回路(グルーロジック)としてPLA(Programmable Logic Array)またはPAL(Programmable Array Logic)が登場した.これらはPLD(Programmable Logic Device)としてFPGAのルーツとなっている.PLAとPALの違いやFPGAに続く発展については,「知識の森・6群5編6章リコンフィギャラブルコンピュータ」を参照されたい.
1990年代も後半になると,集積回路当り1,000万トランジスタが射程に入った.プロセッサの演算性能向上に関する議論は高度化し,スーパスカラやVLIW(Very Long Instruction Word,超長命令語)など,より複雑なアーキテクチャが提案された.また,Intel社のMMXテクノロジーやSSE(Streaming SIMD Extensions,ストリーミングSIMD拡張)など,SIMD(Single Instruction Multiple Data,単一命令複数データ)技術も注目を集めた.プロセッサの動作周波数も1GHzを達成し,プロセッサ単体の性能向上は続いた.
一方,ハードウェアで実装された高度な並列性を高効率に利用するために,投機的実行や分岐予測など,プログラムに含まれる並列性を自動で引き出す工夫が求められるようになった.つまり,ソフトウェア(コンパイラ)の高度化と,ハードウェアにおけるスケジューラの複雑化が進んだ.例えば,ハードウェア面では,演算で必要とする回路規模よりも演算を制御する回路規模の方が大きくなることが懸念された.そこで,シンプルな構造を持つプロセッサを2個備えたデュアルコアプロセッサや,4個ないし8個のプロセッサを備えたマルチコアプロセッサが登場した.
2000年代に入ると,トランジスタ数は数億個という大台に乗ることとなった.これに伴い,Intel社のCore DuoやAMD社のAthlon64X2などデュアルコアプロセッサが一般的となり,MIMD(Multiple Instruction, Multiple Data,複数命令複数データ)形式のシステム実装も増加した.
一方,図1の◆に示されるように,2000年代に入って動作周波数の向上がほぼ止まった.これは,集積回路当りの消費電力▲が頭打ちになったためである.半導体チップ上に実装された集積回路の動作率を ,負荷容量を
,負荷容量を ,電源電圧を
,電源電圧を ,その動作周波数を
,その動作周波数を とすると,消費電力
とすると,消費電力 は以下の式で表される.
は以下の式で表される.

同じ命令数を実行する場合,例えばプロセッサコアを4倍にすると は4倍になるが
は4倍になるが を1/4にできる.
を1/4にできる. の減少により
の減少により を1/2にできるとすると,上式から,消費電力
を1/2にできるとすると,上式から,消費電力 は1/4となる.同等性能でありながら消費電力の削減が見込まれたため,プロセッサ単体の性能よりも,複数のプロセッサを利用する方向への進化が加速された.この傾向は,図1の×で示される集積回路当りのコア数の増加からも確認できる.
は1/4となる.同等性能でありながら消費電力の削減が見込まれたため,プロセッサ単体の性能よりも,複数のプロセッサを利用する方向への進化が加速された.この傾向は,図1の×で示される集積回路当りのコア数の増加からも確認できる.
この時代には,GPUを拡張したGPGPU(General-Purpose Graphic Processing Unit,汎用グラフィックス処理ユニット)が導入され,SIMT(Single Instruction Multiple Thread,単一命令複数スレッド)処理方式が登場した.また,試作用集積回路として利用されていたFPGAもその回路規模を大きくし,テレビやRAID(Redundant Arrays of Inexpensive Disks)の制御など,産業製品に直接組み込む形で利用されるようになった.
集積回路上のトランジスタ数が増加する一方,電力消費と発熱の問題が顕著となり,全てのトランジスタを同時に活用できない「ダークシリコン(4)」の問題が指摘された.これに伴い,電力効率を考慮したマルチコアプロセッサやヘテロジニアスアーキテクチャの進化が加速した.
まず,複数のプロセッサを備えた構成が一般的となり,32コア以上のメニーコアプロセッサも登場した.また,CPUとGPUやCPUとFPGAなど異なる処理機構を同一パッケージに統合したヘテロジニアスアーキテクチャも登場した.代表例としては,AMD社のAPU(Accelerated Processing Unit)やIntel社のAtomプロセッサE660Cなどがある.また,RISC ISAの再評価が進み,オープンかつ拡張性を持たせた命令セットアーキテクチャとしてRISC-V ISAが提案され(3),組込み機器を中心に急速な広がりを見せている.
また,排熱についても対応が進んだ.初期の集積回路では消費電力が低く冷却の必要性は余り高くなかったが,消費電力が高くなると,金属製のヒートシンクが使用され始めた.動作周波数の向上に伴い,ヒートシンクにファンを取り付け,空気の流れを促進して冷却効率を向上させる設計が一般化した.排熱をより効率化するため,銅製のヒートシンクやヒートパイプ,水冷システムに加えて液体金属を用いる冷却技術も導入された.
プロセッサ単体としては,Intel社のx86プロセッサなど,CISCをベースにしつつRISCに似たマイクロ命令に変換して利用するアーキテクチャの融合が加速している.また,AIチップと呼ばれる特定のAIタスク向けに設計されたプロセッサが普及し始めている.これに対し,シストリックアレーやデータフローアーキテクチャの見直しが行われ,これを実現するハードウェアとしてFPGAやCGRA(Coarse-Grained Reconfigurable Architecture)の再評価も進んでいる.
また,量子チップの研究開発が本格化し,実機の制御やシミュレーションにおいてもFPGAが利用されている.更に,チップレット技術も注目されている.チップレットは,チップと呼ばれる小さな独立した集積回路を複数組み合わせて,一つの大きな集積回路のように機能させる技術である.これにより,製造コストの削減や性能向上が期待されている.
半導体集積回路の進化は,CPU,GPU,FPGAを通じて情報処理の効率化と多様化を実現し,現代の情報社会を支えている.これまでの技術的革新は,今後も更なる性能向上や新たな用途開拓を促進するであろう.私たちはこれらの技術を活用し,次世代のイノベーションを創出するために,絶え間ない努力を続けていくことが求められている.
(1) G.E. Moore, “Cramming more components onto integrated circuits,” Electronics, vol.38, no.8, pp.114-117, April 1965.
(2) K. Rupp, “Microprocessor trend data,” Feb. 2022.
[Online]. Available : https://github.com/karlrupp/microprocessor-trend-data.(2024年6月26日アクセス)
(3) A. Waterman, Y. Lee, D.A. Patterson, and K. Asanovic, “The RISC-V instruction set manual, volume I : Base user-level ISA,” Electrical Engineering and Computer Sciences, University of California at Berkeley, Vols. UCB/EECS-2011-62, pp.1-32, 2011.
(4) H. Esmaeilzadeh, E. Blem, R. S. Amant, K. Sankaralingam, and D. Burger, “Dark silicon and the end of multicore scaling,” 38th Annual International Symposium on Computer Architecture, San Jose, 2011.
(2024年7月8日受付 8月30日最終受付)
オープンアクセス以外の記事を読みたい方は、以下のリンクより電子情報通信学会の学会誌の購読もしくは学会に入会登録することで読めるようになります。 また、会員になると豊富な豪華特典が付いてきます。
電子情報通信学会 - IEICE会誌はモバイルでお読みいただけます。
電子情報通信学会 - IEICE会誌アプリをダウンロード

![]()