|
|
電子情報通信学会 - IEICE会誌 試し読みサイト
© Copyright IEICE. All rights reserved.
|
|
|
電子情報通信学会 - IEICE会誌 試し読みサイト
© Copyright IEICE. All rights reserved.
|
解説
大規模言語モデルにおけるハルシネーションの仕組みと対策
Mechanisms of Hallucination in Large Language Models and Countermeasures
A bstract
大規模言語モデル(LLM)の出力には誤り(ハルシネーション)が含まれることが知られている.ハルシネーションは,LLMが事実と異なる情報を出力する現象であり,AI技術の信頼性を大きく損なう可能性がある一方で,LLMの登場初期から現在までいまだ解決されていない重要な課題である.そこで本稿では,ハルシネーションの発生原理に関する考察からその対策手法の紹介を通して,LLMを用いたアプリケーション開発に必要な考え方やLLMとの正しい付き合い方について解説する.
キーワード:大規模言語モデル,自然言語処理,ChatGPT,ハルシネーション,LLM応用
近年,大規模言語モデル(LLM)(用語)の目覚ましい発展により,テキスト生成を伴う多くのタスクにおいて平均的な人間に近しい,またはそれ以上の性能の達成が報告されており(1),AI技術の中でもLLMは特に大きな注目を集めている.しかしその一方,LLMが生成するテキストには事実的な誤り(ハルシネーション(用語))が含まれる場合があり(2),(3),特に医療分野やカスタマーサポート等といった正確な情報が求められるユースケースにおいて社会実装の妨げとなっている.本稿では,ハルシネーションの理解のためにLLMの基本技術について簡単に解説し,ハルシネーションが発生する原因について例を踏まえて考察する.また,LLMを用いたアプリケーション開発を想定し,説得対話や医療向けの要約,観光案内などのユースケースを交えながらハルシネーションのパターンを整理し,その対策について具体的な研究事例に触れながら述べる.最後に,現在のLLMと人間との間の差異という観点から今後の展望を考察する.
現在のLLMは一般的に,事前に学習した単語の共起確率に基づいて次の単語を予測させることを繰り返すことで文章を生成することができる.OpenAI社のGPTやMeta社のLlama, Google社のGeminiといった主要なLLMの多くは注意機構(Attention Mechanism)を含むトランスフォーマ(Transformer)と呼ばれるニューラルネットワークアーキテクチャをベースとしたモデルであり,膨大な量のテキストデータを統計的アプローチによって学習することで作成されている(4).ここでは,これらのモデル構築における最も基本的な学習方法の一例を簡単に説明する.
LLMの事前学習では,次の単語を予測するために次のような目的関数(損失関数)を最小化する方法が一般的に採用されている.

ここで, は
は 番目の単語,
番目の単語, はモデルのパラメータを表す.つまり,
はモデルのパラメータを表す.つまり, 番目までの単語に基づいた最も自然な単語が
番目までの単語に基づいた最も自然な単語が 番目の単語として導き出されるように
番目の単語として導き出されるように を更新することで目的関数を最小化する方向に学習が進む.
を更新することで目的関数を最小化する方向に学習が進む.
単語の予測は図1のように行われる.各入力単語はまず単語の意味的な情報をベクトルで表現した埋込表現(Embedding)へ変換され,注意機構では単語間の関係性が複数の文脈長などを基準に多面的に表現される.その後,最終的に出力層で得られた埋込みに対しソフトマックス関数を用いて次の単語の確率分布 を得る.推論時には得られた確率分布からサンプリングすることで単語を決定するという流れである.
を得る.推論時には得られた確率分布からサンプリングすることで単語を決定するという流れである.
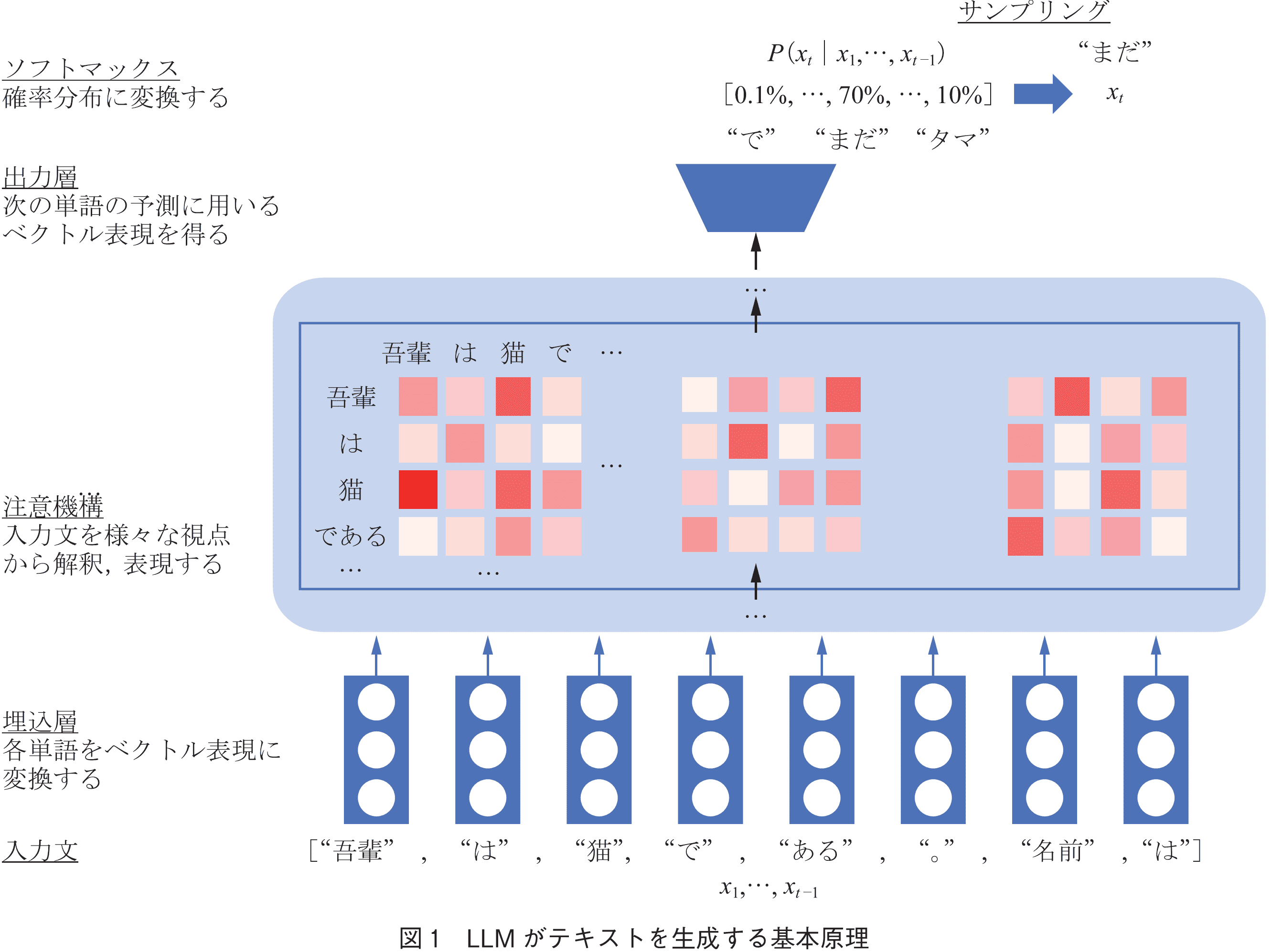
この基本構造はChatGPTに代表されるような対話形式でLLMに指示や質問を与え出力を生成する場合でも同様であり,人間からのフィードバックを用いた強化学習を行うことで指示や質問に続く回答文として適切なものが生成できるよう調整されることが一般的である.また,そうして調整されたLLMは入力文の中で“あなたはQAアシスタントです”や“以下の英文を翻訳しなさい”のような指示を受け付けることが可能であり,そのような入力はプロンプトと呼ばれている.
前章で説明したように,LLMは少なくとも一般的なデータベースのように情報を体系的に整理・保存するのではなく,統計的手法の結果として文法や意味的な規則性を暗黙的にモデル内に形成し,その一部として情報を格納していると言える(注1).格納された情報は,単語の共起性やコンテキスト(文脈)など,何らかの統計的特徴によって引き出されるものと考えられる.また,与えられた入力文の解釈についても何らかの構文解析などのようにシステム化されたものではなく,後続の単語の生成確率が高くなるよう調整された埋め込み表現によるものにすぎない.つまりLLMの出力は,あくまで統計的特徴に基づいて,“もっともらしい”単語の系列を予測して出力しているだけであり,それが必ずしも事実と一致するとは限らない.また,LLMは算出された確率分布から必ずしも最も確率の高い単語を選択するわけではなく,出力に多様性を与えるために低確率の単語を選択する場合もある.こういった特性がハルシネーションを引き起こす要因の一つである可能性があると考えられる.
特に,与えられた文脈に対し“もっともらしい”テキストを生成する傾向は顕著であり,図2にこの特性を利用して意図的に誘発させたハルシネーションの一例を示す.この例ではOpenAI社のGPTの一つであるGPT-4oにセーブ・ザ・チルドレンというNPO団体へ寄付するようユーザを説得するというタスクが与えられている.ユーザは“家庭教師の派遣”という活動に興味を示しており,GPT-4oは説得が成功するような対話を進めるために実際には行われていない活動を説明することで説得してしまい,信頼性を損ねるハルシネーションを生成している.この例のような文脈を与えるとハルシネーションを誘発しやすいことからも,もっともらしいテキストを生成する特性はハルシネーションの一要因となっていると考えられる.ここでは入力文にハルシネーションを誘発するような文脈を設定したが,生成途中に誤ったベクトル表現計算やサンプリングの結果により不適切な単語系列が選択されてしまった際も同様である.

ハルシネーションのパターンについては幾つかの考え方があるが,ここでは出力で示された情報の参照元に基づく2種類の分類を紹介する.一つは内因性ハルシネーション(Intrinsic Hallucination)と呼ばれ,プロンプトや入力文中で与えられている情報を参照した出力に関するハルシネーションであり,もう一つは外因性ハルシネーション(Extrinsic Hallucination)と呼ばれ,LLM内部に格納された情報を参照した出力に関するハルシネーションである.
内因性ハルシネーションとは,入力に含まれる情報を誤って解釈してしまうようなハルシネーションを指す.例えば図3のLLMを用いたカルテ生成の例では,患者の“目の前が少しぼやけることもありますが,視力に問題はないと思います.”という発言からLLMは“視力に関する問題はない”とカルテに記載してしまっている.これは“目の前がぼやける”という重要な情報が不適切に省略されてしまい誤った解釈になった例だと言える.このように,実際のハルシネーションはタスクや文脈によって判断しなければならない場面も多く,解決が容易ではない問題である.
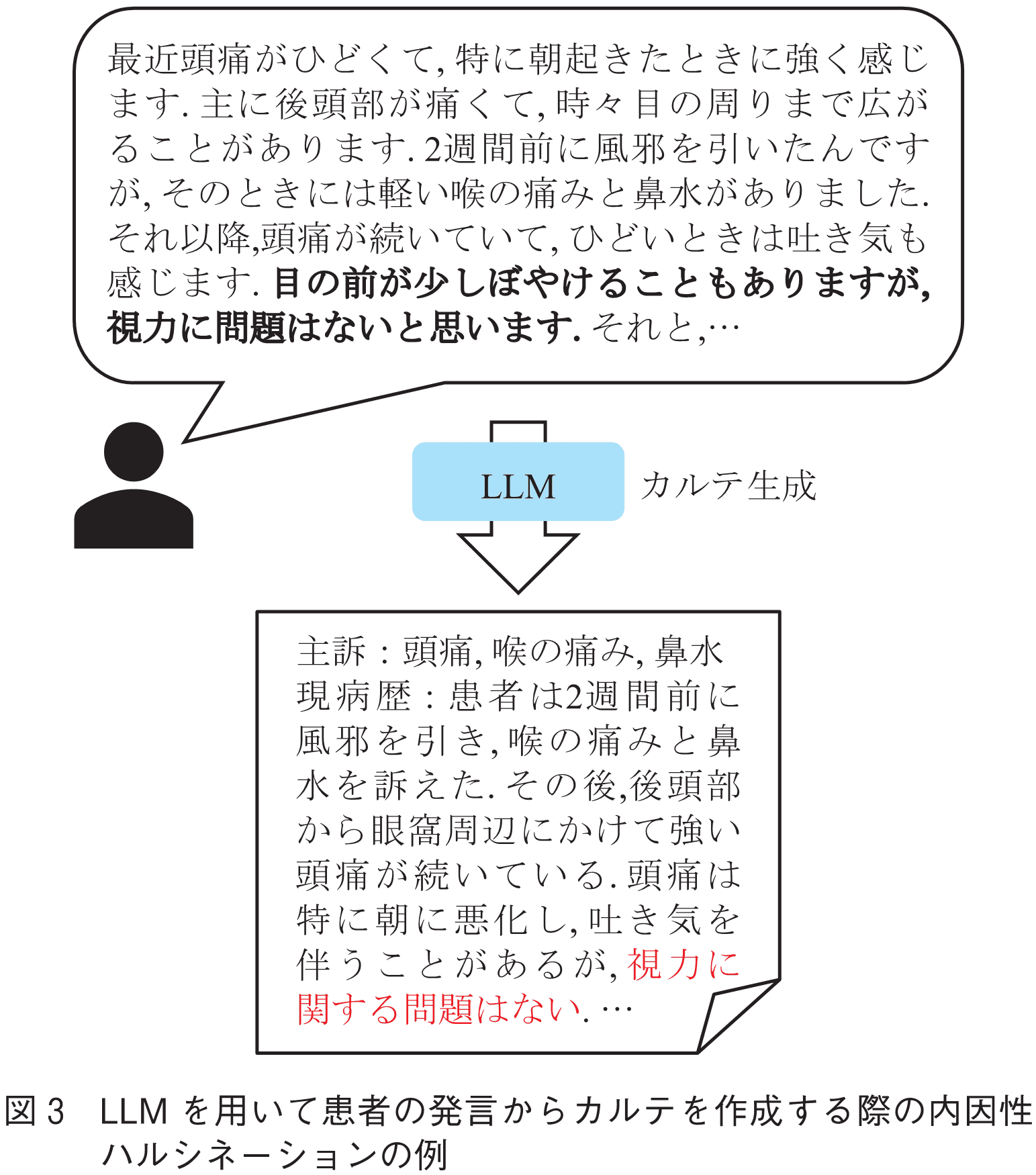
内因性ハルシネーションは主に表現が曖昧であったり複雑な文書,長い文書などの要約過程で見られるハルシネーションであり,議事録や報告書の作成のようなアプリケーションにLLMを応用した場合に特に注意が必要である.また,チャットボットを構成する際に,対話履歴中に示されたユーザ情報を誤って認識しているような発話を生成したり,一貫性を損う自己矛盾するような発話を生成するケースも内因性ハルシネーションに分類される.
内因性ハルシネーションは入力として与えられた情報の範囲内で解釈や要約の結果生じるものであった.一方で外因性ハルシネーションは,LLM内部に格納された情報を利用して出力を生成した際の誤りを指す.そのため,どのような情報が現れるのか事前に予測することが難しく,その発見が容易ではないものが多い.例えば図4に示すような推薦タスクにおいて,LLMはユーザからの要望に対し自身の持つ情報を用いて兵庫県の観光地を推薦している.しかし,兵庫県ではなく奈良県に存在する高取城を推薦してしまっており,また,高取城は日本三名城ではなく日本三大山城として知られている城である.
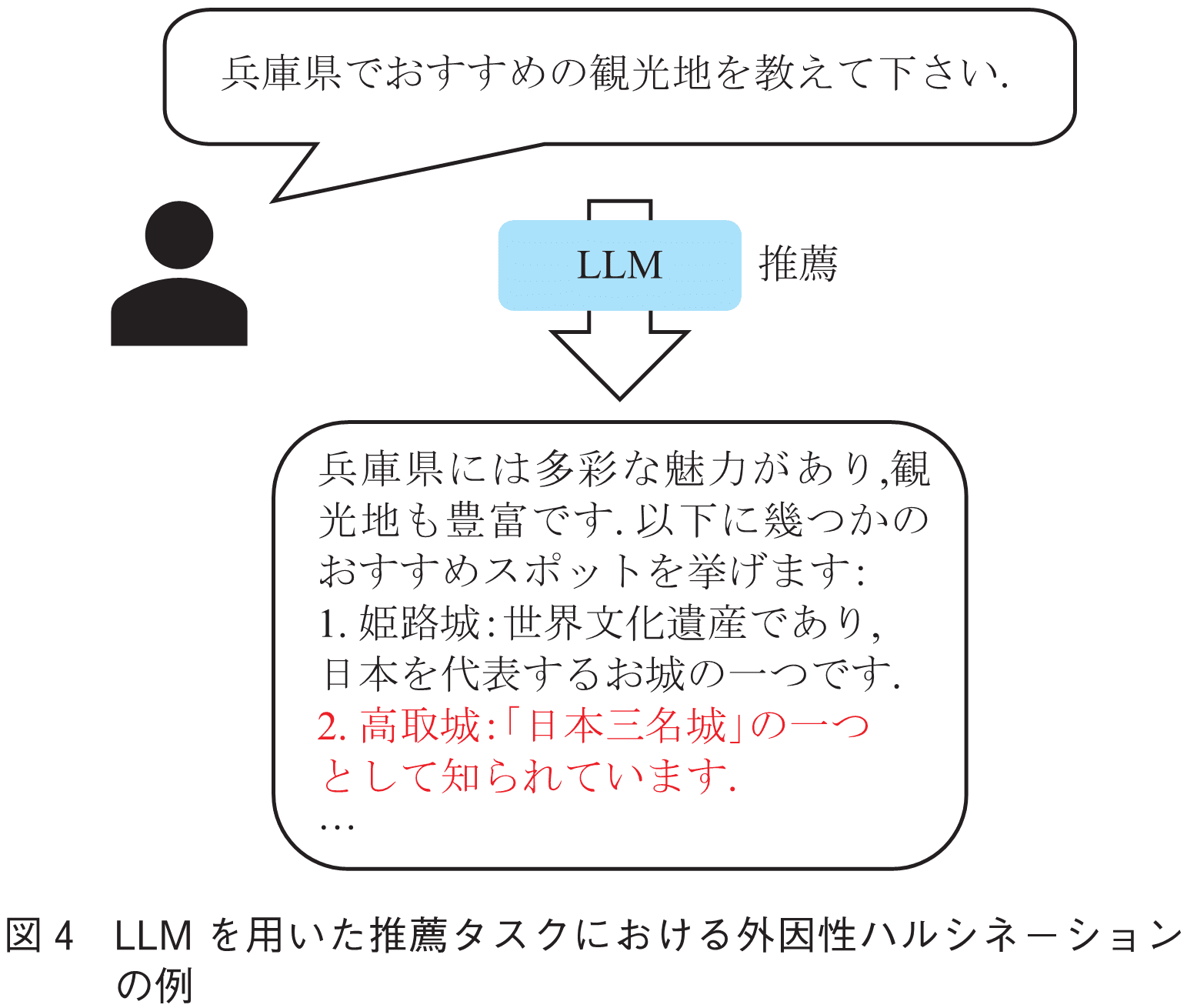
外因性ハルシネーションは主に知識的な応答や推論が求められる場合に見られるハルシネーションであり,質問応答や推薦チャットボットのようなアプリケーションにLLMを応用した場合に特に注意が必要であると考えられる.
ここでは,4.で述べた各ハルシネーションパターンに関するハルシネーション抑制手法や,統一的な抑制手法を紹介する.
内因性ハルシネーションは入力に正しい情報が含まれているのにもかかわらず誤ってしまう問題であるため,入力と出力間の整合性を検証,または向上させるアプローチが有効である.要約タスクにおけるハルシネーション抑制手法として,Shenらは内因性ハルシネーションの多くが会社名やその略称などといった固有名詞に関わるものであることに注目し,LLMの入力文章と要約結果に含まれる固有名詞を含む各単語(エンティティ)を入出力間で適切にひも付けることで整合性を向上させるアルゴリズムを提案した(5).また,Chaeらは,2.で考察したようなLLMが持つもっともらしいテキストを生成するという性質によって入力文書の細部が無視され結果的にハルシネーションを生んでいるという仮説を立て,そのようなモデルバイアスを軽減するために文書のトピックを考慮した条件付きの自己相互情報量に基づく単語選択(デコーディング)戦略を提案した(6).これらのアプローチは学習や推論過程に手を加えることが可能なLlamaなどのオープンソースモデルでは有効な手法であるが,APIによって提供されているChatGPTやGeminiといったLLMでは適用が難しい.
APIベースのモデルでも適用可能な手法として,出力を改めてLLMに入力し評価させる手法が挙げられる.これは“llm-as-a-judge”として知られている手法であり,従来の単語一致度をベースとした出力品質の評価手法と異なり,LLMを用いることでより柔軟で人間が行うものに近い評価を可能にするものである(7),(8).こういった手法を援用し,例えば要約元の文書と矛盾する情報が出力に含まれていないかをLLMに評価させ(9),矛盾があった場合は修正させるなどといった方法で対策することができる.
外因性ハルシネーションはLLM内部に格納された情報に関するものであるため,その抑制手法としてはLLM内部の情報にできるだけ頼らずに済むようにするアプローチが有効である.そのようなアプローチとしてRetrieval Augmented Generation(RAG)と呼ばれるものが最も一般的であり,これは外部のデータベース等と連携し出力に必要と思われるドキュメントを情報ソースとしてあらかじめ取得しLLMへの入力に含めることで事実性を向上させるものである(10).RAGは汎用的に適応でき多くのケースで有効であるが,主に情報ソースの検索方法について実態に合わせて解決すべき幾つかの課題が存在する.ここでは,クエリ設計の課題,検索対象の単純化の課題,タスク達成性能の低下の課題という三つの課題に着目しその対策を紹介する.
クエリ設計の課題について,これは外部ソースを検索するためにユーザ発話等をそのままクエリとして利用すると検索精度が低下する場合があるという課題である.例えばQAタスクにおいて,ユーザの質問文をそのままクエリとして用いるだけではユーザの言い回しや相づちなどといった直接的に関係のない文言が雑音となり検索精度が低下する.この課題に対しSemnaniらは,LLMに“回答に必要な情報を集めるためにはGoogle検索に何と入力すればよいか?”というようなプロンプトを与えることで人間のようなキーワードベースの検索クエリを生成させ,適切な抽象度での検索を可能にした(11).
検索対象の単純化の課題について,これは単一のクエリでは検索範囲が不十分であったり,必要な情報の粒度が表現できない場合があるという課題である.例えば図4の例において,文脈によっては“兵庫県観光地おすすめ”のようなクエリでなく“兵庫一人旅モデルコース”などのクエリがより適切である場合もあるが,それらを判断することは難しく多くの場合で単純なクエリが採用されてしまう.その対策の一つとして,RAG-Fusionというアプローチが挙げられる.これは,あるクエリについて類似しているが異なる表現となるクエリをLLMを用いて多数生成し,それぞれの検索結果を集約,まとめてランキングすることで多様な文脈を考慮した情報検索によるRAGを可能にする手法である(12).
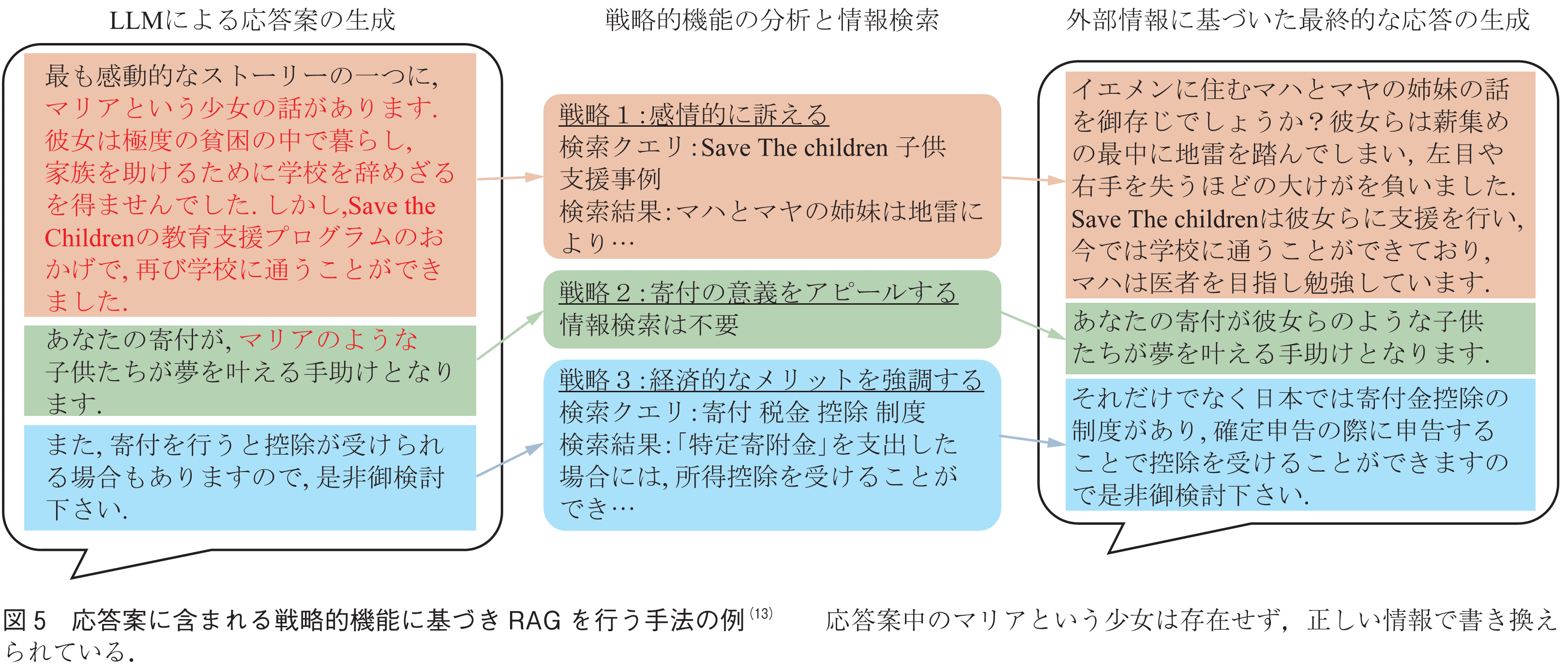
最後にタスク達成性能の低下という課題について,これはユーザ発話を用いたクエリ生成が困難な場合には限られた情報ソースしか取得できずに,生成結果の品質が低下するという課題である.QAや推薦といったタスクでは基本的にユーザから質問や要望が与えられるため適切なクエリの生成が比較的容易であるが,説得や交渉といったタスクではユーザが明示的に要求していない情報も場合によって必要となる.例えばセーブ・ザ・チルドレンへの寄付を説得するようなタスクにおいて,複雑な国際情勢に興味を示さないユーザに対しては感動的な話を共有したり経済的な利点を説明するといった説得戦略の切り替えが必要になる.そのようなケースではユーザ発話に基づくクエリ生成が難しく,不十分な情報ソースによって戦略が制限されタスク達成性能が低下したり,それでも説得を試みることでハルシネーションを引き起こす場合がある.このような課題について古舞らは,あえてハルシネーションも含めた応答案をまず生成させ,それを修正するためにクエリ生成を行うことで解決している.具体的には図5に示すように,LLMが与えられたタスクに従い生成した応答案中に含まれる戦略的機能を分析し,それらの戦略を外部の情報ソースを用いて再現することを目的に検索クエリを生成することでこの課題に対処している.これにより,LLMが本来持つタスク達成性能を損なわずに事実的に正しい説得対話を可能にしている(13).
ハルシネーションのパターンにかかわらず有効な手法について,LLMに推論過程を自然言語で記述させることで出力の精度を向上させる“ステップ・バイ・ステップ”と呼ばれるようなプロンプトエンジニアリングもその一つである(14).更に,近年ではLLMの内部状態を分析することでハルシネーションの検知や修正を行う手法も提案されており,SriramananらはLLMの重みや注意機構,単語の予測確率を用いてハルシネーション検知のためのスコアを算出する手法を提案した(15).また,Chuangらは注意機構の重みを分析することで検出を行う手法を提案しており,入力(文脈)への注意度合いと生成された単語系列の注意度合いの比に基づく検出器を作成した(16).
こういった内部状態を用いて検知を行う手法はその精度以上に高速性に利点がある.LLMを複数回呼び出すアプローチや情報検索を伴うRAGアプローチは,最終的な出力を得るための時間が増加したりと実運用上の課題が生じる場合が多いが,内部状態に基づくアプローチは高速に計算することが可能であり,即応性が求められるアプリケーションにも比較的適用しやすい.
本稿では,大規模言語モデル(LLM)が持つハルシネーションという問題についてその要因を基本技術の観点から考察しそのパターンを解説し,最新のハルシネーション抑制手法を紹介した.LLMは強力なテキスト生成能力を提供する一方で信頼性の観点から社会実装に課題を抱えている.これは,あくまで統計的な振舞いが基本となっているLLMの性質による課題である可能性がある.最新のLLMはおよそ15T単語,本にして約1,500万冊に相当するとも言われる量のテキストで学習されているが(注2),人間はそれよりもはるかに少ない量のテキストで高度な言語能力及び言語に基づく思考能力を獲得できており,自身が理解できていないことや知らないことをある程度自覚することもできる.このような能力に関する取組みが近年増加してきているものの(17),(18),今のAI技術ではモデル化できていない重要な要素が残されている可能性が高く,AGI(汎用人工知能)やASI(人工超知能)のような次世代のAI技術の誕生には学習データ量やモデルサイズの増加による性能向上だけでない革新的な進化が必要ではないかと考える.また,そのような知能を備えなければユーザ側がLLMにわざと誤った発言をさせる,ひいてはだますといった問題を防ぐことも難しい.AI技術の急速な発展に伴い信頼性という観点はますます重要になることが考えられるが,研究者の様々な取組みがこれを解決し,AIと人間が共存するより良い社会の実現に寄与することを期待している.
(1) OpenAI, “GPT-4o system card,” arXiv, Vol.abs/2410.21276, 2024.
(2) J. Maynez, S. Narayan, B. Bohnet, and R. McDonald, “On faithfulness and factuality in abstractive summarization,” Proc. 58th Annual Meeting of the Association for Computational Linguistics, pp.1906-1919, 2020.
(3) C. Zhou, G. Neubig, J. Gu, M. Diab, F. Guzmán, L. Zettlemoyer, and M. Ghazvininejad, “Detecting hallucinated content in conditional neural sequence generation,” in Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp.1393-1404, 2021.
(4) A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A.N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” arXiv, Vol. abs/1706.03762, 2023.
(5) J. Shen, J. Xuan, and C. Liang, “Mitigating intrinsic named entity-related hallucinations of abstractive text summarization,” Proc. 2023 Conference on Empirical Methods in Natural Language Processing, pp.15807-15824, 2023
(6) K. Chae, J. Choi, Y. Jo, and T. Kim, “Mitigating hallucination in abstractive summarization with domain-conditional mutual information,” Findings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics, pp.1809-1820 2024.
(7) L. Zheng, W. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E.P. Xing, H. Zhang, J.E. Gonzalez, and I. Stoica, “Judging LLM-as-a-judge with MT-bench and chatbot arena,” Proc. 37th International Conference on Neural Information Processing Systems, pp.46595-46623, 2023.
(8) Y. Liu, D. Iter, Y. Xu, S. Wang, R. Xu, and C. Zhu, “G-eval: NLG evaluation using Gpt-4 with better human alignment,” Proc. 2023 Conference on Empirical Methods in Natural Language Processing, pp.2511-2522, 2023.
(9) Z. Luo, Q. Xie, and S. Ananiadou, “ChatGPT as a factual inconsistency evaluator for text summarization,” arXiv, Vol.abs/2303.15621, 2023.
(10) P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” Proc. 34th International Conference on Neural Information Processing Systems, pp.9459-9474, 2020.
(11) S.J. Semnani, V.Z. Yao, H.C. Zhang, and M.S. Lam, “WikiChat: Stopping the hallucination of large language model chatbots by few-shot grounding on Wikipedia,” Proc. 2023 Conference on Empirical Methods in Natural Language Processing, pp.2387-2413, 2023.
(12) Z. Rackauckas, “RAG-Fusion: A new take on retrieval-augmented generation,” International Journal on Natural Language Computing, vol.13, no.1, pp.37-47, 2024.
(13) K. Furumai, R. Legaspi, J. Vizcarra, Y. Yamazaki, Y. Nishimura, S.J. Semnani, K. Ikeda, W. Shi, and M.S. Lam, “Zero-shot persuasive chatbots with LLM-generated strategies and information retrieval,” Proc. 2024 Conference on Empirical Methods in Natural Language Processing, pp.11224-11249, 2024.
(14) T. Kojima, S.S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa, “Large language models are zero-shot reasoners,” Proc. 36th International Conference on Neural Information Processing Systems, pp.22199-22213, 2022.
(15) G. Sriramanan, S. Bharti, V.S. Sadasivan, S. Saha, P. Kattakinda, and S. Feizi, “LLM-check: Investigating detection of hallucinations in large language models,” Proc. 38th Annual Conference on Neural Information Processing Systems, 2024.
(16) Y. Chuang, L. Qiu, C. Hsieh, R. Krishna, Y. Kim, and J. Glass, “Lookback lens: Detecting and mitigating contextual hallucinations in large language models using only attention maps,” Proc. 2024 Conference on Empirical Methods in Natural Language Processing, pp.1419-1436, 2024.
(17) M. Xiong, Z. Hu, X. Lu, Y. Li, J. Fu, J. He, and B. Hooi, “Can LLMs express their uncertainty? An empirical evaluation of confidence elicitation in LLMs,” Proc. 12th International Conference on Learning Representations, 2024.
(18) H. Huang, Y. Yang, Z. Zhang, S. Lee, and Y. Wu, “A survey of uncertainty estimation in LLMs: Theory meets practice,” arXiv, Vol. abs/2410.15326, 2024.
(2025年1月29日受付 2025年2月6日最終受付)

■ 用 語 解 説
(注1) ニューラルネットワークの重みの解釈については依然としてブラックボックスとなっている部分が多く,本稿執筆時点では学習された重みが実際にどのような意味を持っているのかを知ることは難しい.
オープンアクセス以外の記事を読みたい方は、以下のリンクより電子情報通信学会の学会誌の購読もしくは学会に入会登録することで読めるようになります。 また、会員になると豊富な豪華特典が付いてきます。
電子情報通信学会 - IEICE会誌はモバイルでお読みいただけます。
電子情報通信学会 - IEICE会誌アプリをダウンロード

![]()